[문과 코린이의 IT 기록장] MSSQL - 데이터 베이스 활용 (테이블 스크립트, 2개 이상의 컬럼을, 기본키로 만들기, CLUSTERED VS NONCLUSTERED, DB내 인덱스 확인, CLUSTERED INDEX / NONCLUSTERED INDEX 실습)

[문과 코린이의 IT 기록장] MSSQL - 데이터 베이스 활용 (테이블 스크립트, 2개 이상의 컬럼을, 기본키로 만들기, CLUSTERED VS NONCLUSTERED, DB내 인덱스 확인, CLUSTERED INDEX / NONCLUSTERED INDEX 실습)
< 참고 강의 영상 >
MSSQL Server 2016 기반의 데이터베이스 입문에서 활용까지 Part.3 대시보드 - 인프런 | 강의 (inflearn.com)
MSSQL Server 2016 기반의 데이터베이스 입문에서 활용까지 Part.3 - 인프런 | 강의
데이터베이스 구축에서부터 테이블 생성, 각종 SQL 쿼리문을 사용해서 데이터베이스 내 데이터를 조작, 변경할 수 있는 강의입니다., - 강의 소개 | 인프런...
www.inflearn.com
2022.01.21 - [문과 코린이의, [SQL] 기록] - [문과 코린이의 IT 기록장] MSSQL - 집계 함수, GROUP BY / HAVING
[문과 코린이의 IT 기록장] MSSQL - 집계 함수, GROUP BY / HAVING
[문과 코린이의 IT 기록장] MSSQL - 집계 함수, GROUP BY / HAVING < 참고 강의 영상 > MSSQL Server 2016 기반의 데이터베이스 입문에서 활용까지 Part.2 대시보드 - 인프런 | 강의 (inflearn.com) M..
vansoft1215.tistory.com
[문과 코린이의 IT 기록장] MSSQL - 서브 쿼리 : IN 연산자, 상관 서브쿼리, 다중 INSERT 여러 방법, 서
[문과 코린이의 IT 기록장] MSSQL - 서브 쿼리 : IN 연산자, 상관 서브쿼리, 다중 INSERT 여러 방법, 서브쿼리 연습문제, IN, EXISTS 연산자, IN, EXISTS 연산자 연습문제 < 참고 강의..
vansoft1215.tistory.com
2022.01.26 - [문과 코린이의, [SQL] 기록] - [문과 코린이의 IT 기록장] MSSQL - GROUP BY 추가 설명, 다중 그룹
[문과 코린이의 IT 기록장] MSSQL - GROUP BY 추가 설명, 다중 그룹
[문과 코린이의 IT 기록장] MSSQL - GROUP BY 추가 설명, 다중 그룹 < 참고 강의 영상 > MSSQL Server 2016 기반의 데이터베이스 입문에서 활용까지 Part.2 대시보드 - 인프런 | 강의 (inflearn.com)..
vansoft1215.tistory.com
1. 테이블 스크립트
1) 데이터베이스 생성 추가 학습
-- 데이터 베이스 생성
CREATE DATABASE 77TESTDB; -- 에러 발생 (숫자로 시작하는 경우)
CREATE DATABASE [77TESTDB]; -- 에러 X
-- 작업 DB 변경
USE 777TESTDB; -- 에러 발생
USE [77TESTDB]; -- 에러 X
2) Intro
ex. 쇼핑몰 테이블 구성
/*
일반적인 쇼핑몰에서 볼 수 있는 전형적인 테이블 구성
1) dbo.tbl_members : 고객 테이블 (회원가입 테이블)
2) dbo.tbl_sales1 : 매출테이블 1 (주문 테이블)
3) dbo.tbl_sales2 : 매출테이블 2 (장바구니 테이블)
4) dbo.tbl_goods : 상품테이블
5) dbo.tbl_vendors : 판매테이블
*/
-- 데이터베이스 생성
CREATE DATABASE [77TESTDB];
-- 작업 DB 변경
USE [77TESTDB];
-- 기본 테이블 생성 스크립트
CREATE TABLE tbl_members(
m_id CHAR(10) PRIMARY KEY, -- PRIMARY KEY는 NOT NULL을 자동으로 포함 (NOT NULL을 따로 써줘도 됨)
m_name CHAR(50) NOT NULL,
m_address CHAR(300) NULL,
m_country CHAR(50) , -- 이는 NULL,과 같은 것 (안 써주면 디폴트)
m_tel CHAR(50) , -- 전화번호는 일반적으로 문자로 입력받음 (숫자X)
m_email CHAR(300)
);2. 2개 이상의 컬럼을, 기본키로 만들기
- 매출(주문) 테이블 생성시, 한 명이 여러개의 물건을 구매하는 경우(결제는 한번에 함. 주문 내역서는 하나)를 고려한다.
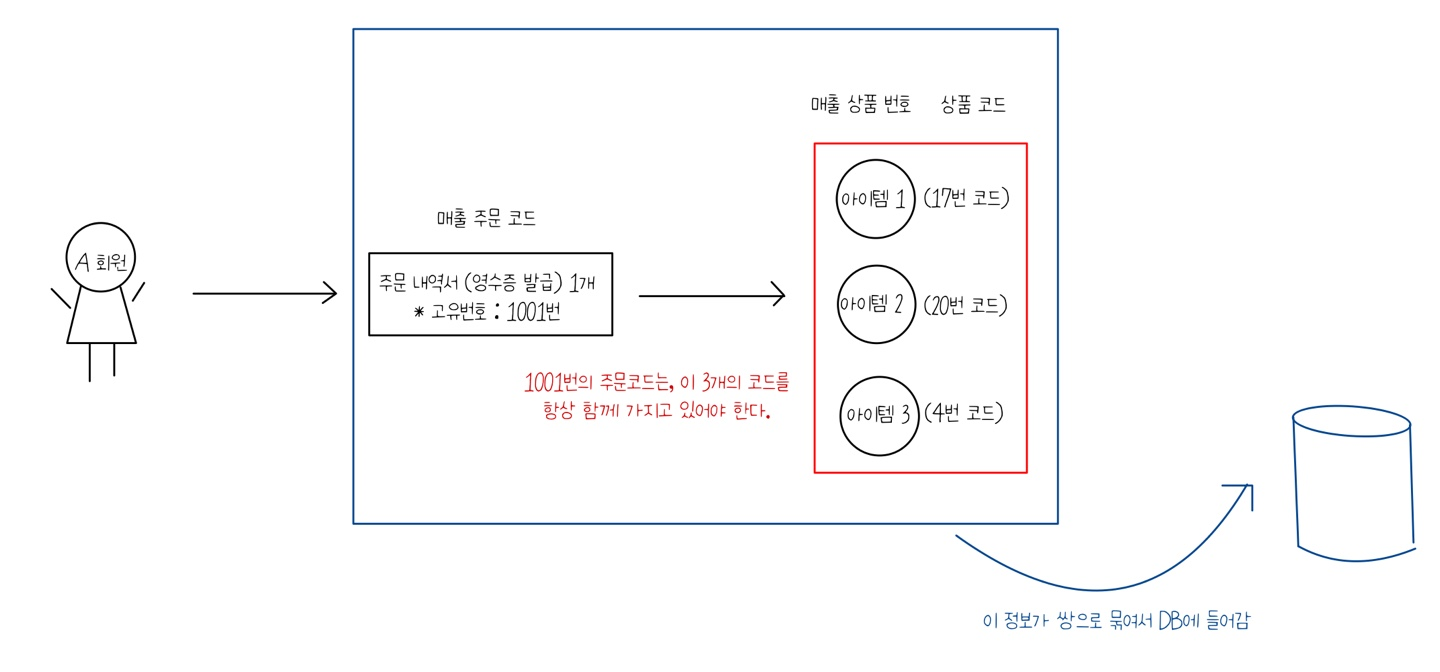
* DB 표현
| 1001 | 1 | 17 |
| 1001 | 2 | 20 |
| 1001 | 3 | 4 |
** 10010117 / 10010220 / 10010304 -> 두 개의 컬럼을 하나의 컬럼으로 만들어진 것
- 이와 같이, 실제 DB 구성시에는 '매출 주문 코드' + '매출 상품 번호' + ' 상품 코드'를 묶어서 하나의 기본키로 구성하면 좋다.
* 두 개가 묶여서 하나의 컬럼과 같은 역할을 하는 것. (두개의 컬럼 x)
ex 1. 기본키 테이블 구성 - error : 하나의 값 기본키 구성
-- primary key 1 (error)
CREATE TABLE tbl_primarykey(
A INT NOT NULL PRIMARY KEY, -- 이 컬럼은 중복 불가능.
B INT NOT NULL ,
C INT NOT NULL
);
INSERT INTO tbl_primarykey VALUES(1001, 1, 101);
INSERT INTO tbl_primarykey VALUES(1002, 1, 201);
INSERT INTO tbl_primarykey VALUES(1002, 1, 301); -- 에러 발생. 기본키 지정 컬럼이 중복 발생ex 2. 기본키 테이블 구성 - 2개 이상의 컬럼을 기본키로 구성
-- primary key 2
CREATE TABLE tbl_primarykey(
A INT NOT NULL,
B INT NOT NULL,
C INT NOT NULL
PRIMARY KEY CLUSTERED( -- 한 컬럼을 제외한, 나머지 컬럼들은 중복 가능하다. (모두 합쳐져서 중복이 안되면 됨)
A,
B,
C
)
);
INSERT INTO tbl_primarykey VALUES(1001, 1, 101);
INSERT INTO tbl_primarykey VALUES(1002, 1, 201);
INSERT INTO tbl_primarykey VALUES(1002, 1, 203);
INSERT INTO tbl_primarykey VALUES(1002, 2, 201);ex 3. 기본키 테이블 구성
-- primary key 3
CREATE TABLE dbo.tbl_test99(
A INT NOT NULL,
B INT NOT NULL,
C CHAR(10) NOT NULL
PRIMARY KEY CLUSTERED(
A,
B,
C
)
);
INSERT INTO dbo.tbl_test99 VALUES(1,1,'GT101');
INSERT INTO dbo.tbl_test99 VALUES(1,2,'GR201');
INSERT INTO dbo.tbl_test99 VALUES(1,3,'GC301');
INSERT INTO dbo.tbl_test99 VALUES(1,3,'GR201');* 기본키의 중요성 : 기본키 설정을 하지 않으면 데이터를 찾는데 속도가 굉장히 느려짐. (효과적이지 않음)
=> 기본키를 설정하는 것은, 목차를 만드는 것과 같음
* 기본키의 특징 : Not Null, 중복 불가능
[문과 코린이의 IT 기록장] MSSQL - 기본키, 외래키 ( 기본키 (Primary Key) , 외래키 (Foreign Key), 관계형
[문과 코린이의 IT 기록장] MSSQL - 기본키, 외래키 ( 기본키 (Primary Key) , 외래키 (Foreign Key), 관계형 데이터베이스란?) < 참고 강의 영상 > MSSQL Server 2016 기반의 데이터베이스..
vansoft1215.tistory.com
3. CLUSTERED VS NONCLUSTERED
- CLUSTERED 인덱스 : 책 앞부분의 '목차'와 같은 것 (이미 순서/정렬이 되어 있는 것 ex. 사전)
* 하나만 만들 수 있음.
* 대표적인 방법이 PRIMARY KEY임. 내부에서 CLUSTERED INDEX를 자동으로 구현해줌.
CREATE TABLE tbl_customers
(
cus_id CHAR(6) NOT NULL PRIMARY KEY,
cus_name NVARCHAR(20),
cus_class NVARCHAR(20),
-- cus_id를 PRIMARY KEY로 지정하면, 자동으로 CLUSTERED INDEX가 생성
-- PRIMARY KEY(CLUSTERED INDEX)는 테이블 당 한개만 생성 가능하다.
);- NONCLUSTERED 인덱스 : 책 뒷부분의 '색인'과 같은 것
* 하나만 만들 수 있는 것은 아님.
ex. 같은 단어를 영어 / 한글 등으로 나눠서 구현 가능
|
1.색인은 여러 개를 만들 수 있다.
2.영어 색인 ( sub query … 200p )
3.한글 색인 ( 서브 쿼리 … 200p, 300p, 400p )
4.기호 색인 ( & … 245p / ++ … 360p )
|
CREATE TABLE tbl_customers
(
cus_id CHAR(6) NOT NULL PRIMARY KEY, -- clustered index가 만들어져 있음.
cus_name NVARCHAR(20) UNIQUE,-- 추가적으로 nonclustered index를 추가 (UNIOQUE 중복 불가능)
cus_class NVARCHAR(20) UNIQUE
-- 테이블 내 NONCLUSTERED INDEX는 여러개를 생성 가능하다.
-- PRIMARY KEY로 지정된 열이 아닌, 다른 컬럼에 UNIQUE를 지정해주면 해당 열에서는 NONCLUSTERED INDEX가 적용된다.
/*
왜 PRIMARY KEY와 UNIQUE가 지정되면, DB는 내부에서 자동적으로 인덱스를 만들어내는 것인가?
: 중복되지 않는 값들이 지정되는 경우에는, DB가 자동적으로 인덱스를 만들
*/
);4. DB내 인덱스 확인
-- 형식
EXEC SP_HELPINDEX 테이블명;
-- EX)
EXEC SP_HELPINDEX tbl_primarykey;
EXEC SP_HELPINDEX tbl_customers;
5. CLUSTERED INDEX / NONCLUSTERED INDEX 실습
| a. CLUSTERED INDEX와 NONCLUSTERED INDEX 생성을 확인 b. 다양한 값을 입력하여, 인덱스가 생성된 테이블과, 그렇지 않은 테이블간의, 정렬 상태를 비교 c. 인덱스 보기 |
1) INDEX 존재하는 경우 (CLUSTERED INDEX & NONCLUSTERED INDEX)
-- CLUSTERED INDEX & NONCLUSTERED INDEX
CREATE TABLE dbo.tbl_customers
(
cus_id CHAR(10) NOT NULL PRIMARY KEY, -- clustered index DB 내부에서 자동 생성
cus_name NVARCHAR(20) NOT NULL UNIQUE, -- nonclustered index 생성
cus_class NVARCHAR(20) NOT NULL UNIQUE
);
-- CHECK INDEX
EXEC SP_HELPINDEX tbl_customers;
-- INSERT (CLUSTERED INDEX - 자동 정렬 해줌)
INSERT INTO dbo.tbl_customers VALUES('CCC','홍길동','씨앗1');
INSERT INTO dbo.tbl_customers VALUES('BBB','장길동','씨앗2');
INSERT INTO dbo.tbl_customers VALUES('AAA','김길동','씨앗3');
INSERT INTO dbo.tbl_customers
VALUES
('YYY','황길동','씨앗4'),
('ZZZ','곽길동','씨앗5'),
('NNN','조길동','씨앗6'),
('AAAA','은길동','씨앗7');
-- SELECT
SELECT * FROM dbo.tbl_customers;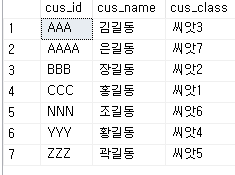
2) NO INDEX
-- NO INDEX
CREATE TABLE dbo.tbl_customers2 -- 이 테이블의 컬럼들에 중복되는 값이 얼마든지 들어올 수 있다. (테이블에 인덱스가 아에 존재하지 않는다.)
(
cus_id CHAR(10) NOT NULL,
cus_name NVARCHAR(20) NOT NULL,
cus_class NVARCHAR(20) NOT NULL
);
-- CHECK INDEX
EXEC SP_HELPINDEX tbl_customers2;
-- INSERT (기본적으로 중복값이 들어와도 되며, 정렬도 해주지 않음. 들어온대로만 저장)
INSERT INTO dbo.tbl_customers2 VALUES('CCC','홍길동','씨앗1');
INSERT INTO dbo.tbl_customers2 VALUES('BBB','장길동','씨앗2');
INSERT INTO dbo.tbl_customers2 VALUES('AAA','김길동','씨앗3');
INSERT INTO dbo.tbl_customers2
VALUES
('YYY','황길동','씨앗4'),
('ZZZ','곽길동','씨앗5'),
('NNN','조길동','씨앗6'),
('AAAA','은길동','씨앗7');
-- SELECT
SELECT * FROM dbo.tbl_customers2;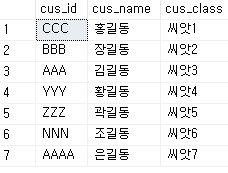
| * 유의사항 - 아직 공부하고 있는 문과생 코린이가, 정리해서 남겨놓은 정리 및 필기노트입니다. - 정확하지 않거나, 틀린 점이 있을 수 있으니, 유의해서 봐주시면 감사하겠습니다. - 혹시 잘못된 점을 발견하셨다면, 댓글로 친절하게 남겨주시면 감사하겠습니다 :) |