[문과 코린이의 IT 기록장] RDBMS Modeling 기초 - Anomaly(이상현상)란?, 정규화 맛보기, 제 1 정규화, 제 2 정규화, 제 3 정규화, BC 정규화, 역정규화)

[문과 코린이의 IT 기록장] RDBMS Modeling 기초 - Anomaly(이상현상)란?, 정규화 맛보기, 제 1 정규화, 제 2 정규화, 제 3 정규화, BC 정규화, 역정규화)
RDBMS Modeling 기초 - 인프런 | 강의
본 강좌는 데이터베이스 설계 이론을 실습 위주로 쉽게 풀어냈습니다. 책 등을 통해서 경험하신 분들은 대부분 데이터베이스 이론이 어렵다고 느끼고 포기하신 경험들이 있을 겁니다. 저도 그
www.inflearn.com
1. Anomaly(이상현상)란?
- 데이터 모델링에서 가장 중요한 것은, 무결성을 보장하는 것이다.
- Anomaly는 중복때문에 발생하며, Update Delete, Insert에서 발생할 수 있다.
* Anomaly를 없애게 되면, 즉 중복을 없애게 되면, 1:1, 1:M, M:N의 관계로 되돌아가게 된다.
ex 1. 갱신 이상
| 번호 (PK) | 이름 | 핸드폰번호 | 사용 서비스 (PK) |
| 10 | 홍길동 | 010-1234-5678 | a서비스 |
| 10 | 홍길동 | 010-1234-5678 | b서비스 |
| 10 | 홍길동 | 010-1234-5678 | c서비스 |
만약 a서비스를 사용하는 홍길동 고객의 핸드폰 번호를 변경한다면? (update)
| 번호 (PK) | 이름 | 핸드폰번호 | 사용 서비스 (PK) |
| 10 | 홍길동 | 010-1324-5789 | a서비스 |
| 10 | 홍길동 | 010-1234-5678 | b서비스 |
| 10 | 홍길동 | 010-1234-5678 | c서비스 |
b서비스 및 c서비스에서는, 해당 고객이 번호가 변경되었다는 것을 인지하지 못한다.
이는 테이블에서 홍길동이 중복으로 나타나고 있기 때문에 발생하는 현상이다.
만약 정규화를 마치고 나면, 홍길동의 속성인 핸드폰번호를 한번만 변경하게 되면, 전체가 갱신되는 것과 마찬가지인 효과를 발생시킬 수 있다.
ex 2. 삭제 이상
| 번호 (PK) | 이름 | 핸드폰번호 | 사용 서비스 (PK) |
| 12 | 김길동 | 010-1234-5678 | a서비스 |
| 12 | 김길동 | 010-1234-5678 | b서비스 |
| 12 | 김길동 | 010-1234-5678 | c서비스 |
김길동 고객의 정보를 삭제하니, 사용 서비스 또한 사라지게 된다.
고객의 정보를 삭제하더라도, 서비스 내역들은 존재하도록 하려면, 정규화를 진행해야 한다.
ex 3. 삽입 이상
| 번호 (PK) | 이름 | 핸드폰번호 | 사용 서비스 (PK) |
| 15 | 장길동 | 010-1234-5678 |
만약 장길동이라는 새로운 선수를 해당 테이블에 등록하고자 할 때, PK인 사용 서비스가 결정되지 않으면 입력할 수 없게 된다. 즉 이와 같이, 다른 데이터가 존재하지 않아, 원하는 데이터를 입력할 수 없게 되는 문제가, 삽입 이상 현상이다.
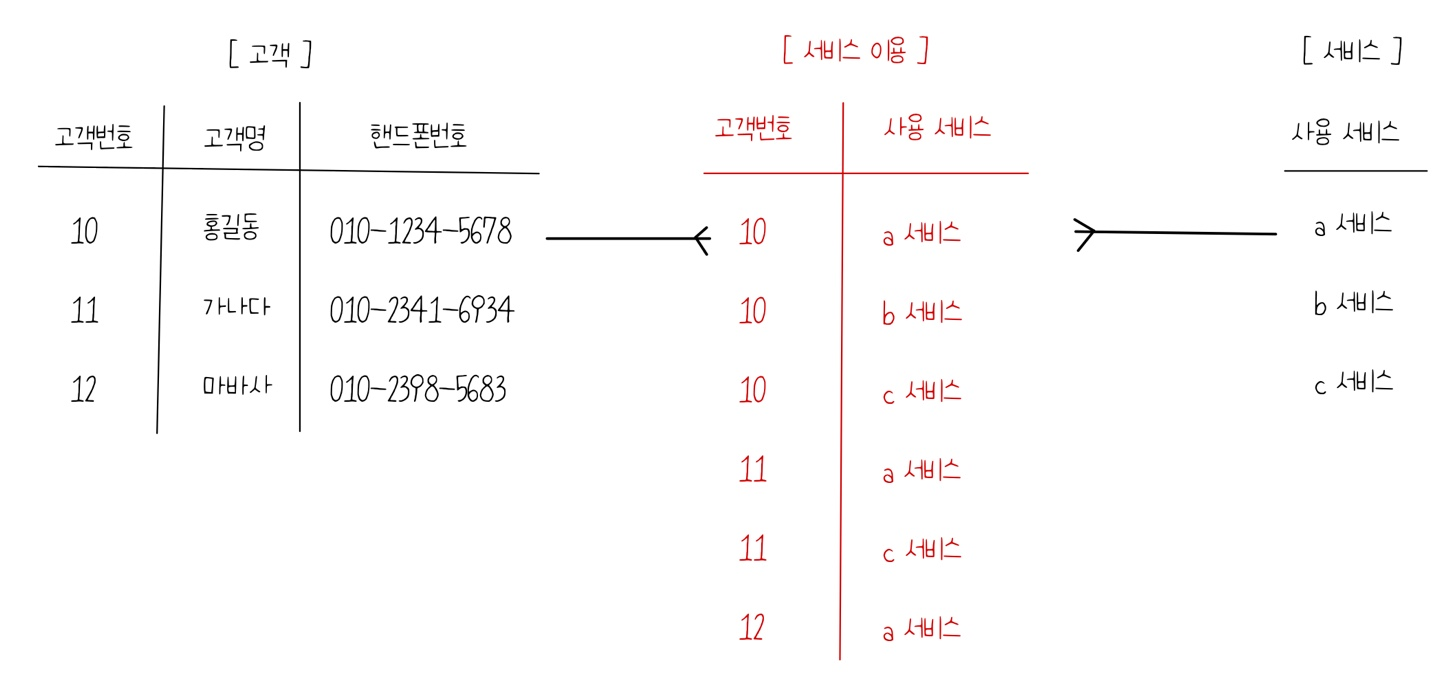
마스터 테이블에는 반드시 레코드가 중복되지 않도록 설계되어야 한다.
중복은 관계형 테이블에서 발생하며, FK를 통해서만 중복 레코드를 입력할 수 있다.
위의 이상 현상에서 보여지는 레포트들은, 조인된 결과 테이블로만 보여지는 것이며, 실제 마스터 테이블에서는 저런 형태로 설계가 불가능하다.
2. 정규화 맛보기
| 주문번호 | 날짜 | 성명 | 연락처 | 주문상품 |
| 1 | 1/1 | 박준용 | 010-xxx | 01배1박스, 02사과 10박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 03콩1kg, 04두부 2모 |
| 3 | 2/5 | 박준용 | 010-xxx | 05쌀20kg, 06보리1kg |
위의 테이블은 중복이 발생한 테이블이다.
'주문상품' 컬럼을 보면 ' , '를 통해 내역들이 구분되어 있다.
이는 해당 테이블이 다가속성을 지니고 있다고 이야기할 수 있다.
다가속성이란, 반드시 한 컬럼은 하나의 속성만 가져야한다는 규칙을 위반한 경우를 이야기한다.
1) 제 1 정규화
아래는, 위 테이블에서 '주문상품' 컬럼 다가속성을 해제한 결과이다.
| 주문번호 | 날짜 | 성명 | 연락처 | 주문상품 |
| 1 | 1/1 | 박준용 | 010-xxx | 01배1박스 |
| 1 | 1/1 | 박준용 | 010-xxx | 02사과 10박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 03콩1kg |
| 2 | 2/1 | 김재진 | 010-xxx | 04두부 2모 |
| 3 | 2/5 | 박준용 | 010-xxx | 05쌀20kg |
| 3 | 2/5 | 박준용 | 010-xxx | 06보리1kg |
다가속성을 해제했음에도, 아직 '주문상품'컬럼은 코드 + 상품 이름 + 상품 수량이 하나의 속성인 것처럼 붙어있는, 복합속성이 존재한다.
아래는, 위의 테이블에서 복합 속성을 해제한 결과이다.
* 다가속성을 해제하면 레코드가 증가하며, 복합속성을 해제하면 컬럼이 증가한다.
| 주문번호 | 날짜 | 성명 | 연락처 | 상품코드 | 상품명 | 개수 |
| 1 | 1/1 | 박준용 | 010-xxx | 01 | 배 | 1박스 |
| 1 | 1/1 | 박준용 | 010-xxx | 02 | 사과 | 10박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 01 | 배 | 1박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 03 | 두부 | 2모 |
| 3 | 2/5 | 박준용 | 010-xxx | 02 | 사과 | 5박스 |
| 3 | 2/5 | 박준용 | 010-xxx | 03 | 두부 | 4모 |
이제 해당 테이블에서 다가속성과 복합속성은 모두 해제되었다.
| 주문번호 | 날짜 | 성명 | 연락처 | 상품코드 | 상품명 | 개수 |
| 1 | 1/1 | 박준용 | 010-xxx | 01 | 배 | 1박스 |
| 1 | 1/1 | 박준용 | 010-xxx | 02 | 사과 | 10박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 01 | 배 | 1박스 |
| 2 | 2/1 | 김재진 | 010-xxx | 03 | 두부 | 2모 |
| 3 | 2/5 | 박준용 | 010-xxx | 02 | 사과 | 5박스 |
| 3 | 2/5 | 박준용 | 010-xxx | 03 | 두부 | 4모 |
그런데 다가속성을 해제하는 과정에서, 아래와 같이 '주문번호', '날짜', '성명', '연락처' 컬럼에서 데이터 중복을 발생시킨 것을 확인할 수 있다.
이러한 데이터 중복을 제거하기 위해서는, 해당 부분들을 별도의 테이블로 독립시켜 분할하는 과정이 필요하다.
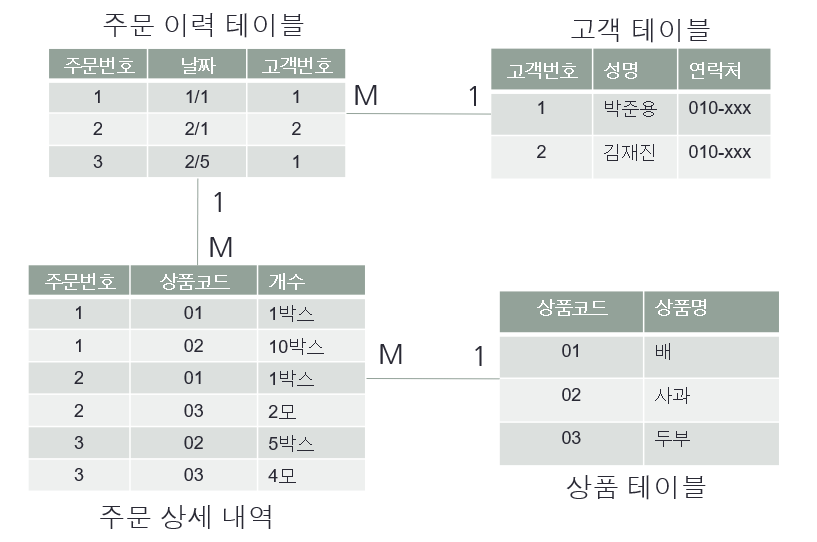
| 주문번호 (PK) | 날짜 | 성명 | 연락처 |
| 1 | 1/1 | 박준용 | 010-xxx |
| 2 | 2/1 | 김재진 | 010-xxx |
| 3 | 2/5 | 박준용 | 010-xxx |
| 주문번호 (PK + FK) | 상품 코드 (PK) | 상품명 | 개수 |
| 1 | 01 | 배 | 1박스 |
| 1 | 02 | 사과 | 10박스 |
| 2 | 01 | 배 | 1박스 |
| 2 | 03 | 두부 | 2모 |
| 3 | 02 | 사과 | 5박스 |
| 3 | 03 | 두부 | 4모 |
주문번호를 통해 두 개의 테이블 간 PK-FK 즉, 1:M관계를 형성하고 있다.
이 과정이 제 1 정규화 과정이다.
2) 제 2 정규화
제 2 정규화는, 하나의 테이블에서 PK가 2개 이상 존재할 때, 어느 일반 컬럼이 모든 PK에 종속되지 않고, 일부 PK에만 종속될 경우, 이를 처리하는 과정을 의미한다.
| 주문번호 (PK) | 상품 코드 (PK) | 상품명 | 개수 |
| 1 | 01 | 배 | 1박스 |
| 1 | 02 | 사과 | 10박스 |
| 2 | 01 | 배 | 1박스 |
| 2 | 03 | 두부 | 2모 |
| 3 | 02 | 사과 | 5박스 |
| 3 | 03 | 두부 | 4모 |
위 테이블에서는, '주문번호'와 '상품코드' 컬럼이 PK이지만, '상품명'의 경우 '상품코드'에만 관련이 있지, '주문번호'에는 종속되지 않는다는 문제가 발생한다. 따라서 이를 처리하는 과정이 필요하다.
이 경우 '상품 코드' 컬럼을 기준으로 테이블을 분할해, 관계를 형성한다.
| 상품 코드 (PK) | 상품명 |
| 01 | 배 |
| 02 | 사과 |
| 01 | 배 |
| 03 | 두부 |
| 02 | 사과 |
| 03 | 두부 |
| 주문번호 (PK) | 상품 코드 (FK) | 개수 |
| 1 | 01 | 1박스 |
| 1 | 02 | 10박스 |
| 2 | 01 | 1박스 |
| 2 | 03 | 2모 |
| 3 | 02 | 5박스 |
| 3 | 03 | 4모 |
3) 제 3 정규화
제 3 정규화는, 식별자 이외 일반속성들 중에, 속성 간 종속관계가 존재하면 안된다는 것이다.
| 주문번호 (PK) | 날짜 | 성명 | 연락처 |
| 1 | 1/1 | 박준용 | 010-xxx |
| 2 | 2/1 | 김재진 | 010-xxx |
| 3 | 2/5 | 박준용 | 010-xxx |
위 테이블에서는, '성명'과 '연락처' 속성이 PK인 주문번호와 관계없이 서로 영향을 주고 있다. 즉, 성명에 따라 연락처가 자동으로 결정되어 버린다는 것이다.
이는 제 3 정규형을 위반하는 것이며, 정규화를 진행하면 아래와 같은 결과가 나온다.
* 정규화 과정은 관계를 가지는 일반 속성들을 뽑아내 테이블을 분할한 후, 해당 테이블에서 PK를 새롭게 설정한다. 이후, 새로운 테이블의 PK를 가져와서 기존 테이블에 추가해준다.
| 주문번호 (PK) | 날짜 | 고객번호 (FK) |
| 1 | 1/1 | 1 |
| 2 | 2/1 | 2 |
| 3 | 2/5 | 1 |
| 고객번호 (PK) | 성명 | 연락처 |
| 1 | 박준용 | 010-xxx |
| 2 | 김재진 | 010-xxx |
4) 1,2,3 정규화를 진행한 최종 결과
3. 제 1 정규화
- 모든 속성(컬럼)은 반드시 하나의 값을 가져야 한다. 이것을 위배하게 되면 중복이 발생한다.
- 값이라는 것은 원자성(ATOM)을 가져야 한다. 즉, 더 이상 쪼갤 수 없는 하나의 값만을 가져야 한다.
* 다가속성(값이 여러개 있는 것) 1정규형 위배
* 복합속성(하나의 단어인 줄 알았지만, 쪼갤 수 있는 단어) 1정규형 위배
1) 1정규화 대상
- 다가 속성이 사용된 테이블
- 복합 속성이 사용된 테이블
- 유사한 속성이 반복된 테이블
- 중첩 테이블
- 동일 속성이 여러 테이블에 사용된 경우
2) 다가 속성이 사용된 테이블
| 고객번호 (PK) | 고객명 | 주민번호 | 전화번호 |
| 100 | 홍길동 | 123456-7890123 | 123-4568, 234-5678, 345-6789 |
| 101 | 황진이 | 234567-8901234 | 456-7890, 567-8901 |
- 다가 속성은 같은 종류의 값을 여러개 가지는 속성을 의미한다.
- 고객 번호를 알더라도, 유일하게 식별할 수 있는 전화번호가 없다. ex. 고객번호 -> 전화번호 ??? (여러개 존재)
- 따라서 전화번호는 주 식별자인 고객번호에, 함수적으로 종속되지 않았다.
a. 한 속성이 하나의 값을 가지도록 풀어보면?
| 고객번호 (PK) | 고객명 | 주민번호 | 전화번호 |
| 100 | 홍길동 | 123456-7890123 | 123-4568 |
| 100 | 홍길동 | 123456-7890123 | 234-5678 |
| 100 | 홍길동 | 123456-7890123 | 345-6789 |
| 101 | 황진이 | 234567-8901234 | 456-7890 |
| 101 | 황진이 | 234567-8901234 | 567-8901 |
b. 고객번호, 고객명, 주민번호에 대한 중복을 제거하면?
[ 고객 ] 테이블
| 고객번호 (PK) | 고객명 | 주민번호 |
| 100 | 홍길동 | 123456-7890123 |
| 101 | 황진이 | 234567-8901234 |
[ 전화번호 ] 테이블
| 고객번호 (FK) | 전화번호 (PK) |
| 100 | 123-4568 |
| 100 | 234-5678 |
| 100 | 345-6789 |
| 101 | 456-7890 |
| 101 | 567-8901 |
- [ 고객 ] 테이블과 [ 전화번호 ] 테이블은 1:M 관계를 가진다.
- 결과적으로, 전화번호가 더 이상 쪼갤 수 없는 고유한 값으로 정리가 되었다.
3) 복합 속성이 사용된 테이블
| 고객번호 (PK) | 고객명 | 주민번호 |
| 100 | 홍길동 | 123456-7890123 |
- 고객명은 성 + 이름으로 구성된, 복합속성이다.
- 만약 고객의 성과 이름을 따로 조회해야 하는 경우가 효율적이라고 판단되면, 이를 분리해야 할 필요가 있다.
* 상황에 따라 다르게 결정하기. (복합속성으로서 의미가 있다고 판단될때만 나누기)
* 이렇게 따지면, 주민번호도 복합속성이 될 수 있다. ( 생년 + 월 + 일 + 성별 + 지역 + 고유번호 )
| 고객번호 (PK) | 고객성 | 고객명 | 주민번호 |
| 100 | 홍 | 길동 | 123456-7890123 |
4) 유사한 속성이 반복된 테이블
| 주문번호 (PK) | 고객번호 | 주문일자 | 상품번호 | 주문수량 | 상품번호2 | 주문수량2 |
| 1234 | 100 | 1998 | P0001 | 2 | A0001 | 1 |
| 1235 | 101 | 2018 | B0002 | 1 | Null | Null |
- 1 정규형은 모든 속성이 단일값을 사용해야 하며, 한 테이블에서 반복 형태의 속성이 존재해서는 안된다.
- 그런데 위의 테이블에서는, 주문번호와 상품번호가 존재함에도, 같은 주문번호 내에 다양한 상품이 존재하므로, 옆으로 계속 늘어난다. 이 경우 문제가 발생할 수 있다.
- 위의 테이블 중, 반복되는 부분을 독립시켜, 1:M 관계를 형성하면 아래와 같은 결과가 나온다.
| 주문번호 (PK) | 고객번호 | 주문일자 |
| 1234 | 100 | 1998 |
| 1235 | 101 | 2018 |
| 주문번호 (PK + FK) | 상품번호 (PK) | 주문수량 |
| 1234 | P0001 | 2 |
| 1234 | A0001 | 1 |
| 1235 | B0002 | 1 |
| 1235 | C0002 | 1 |
| 1235 | B0001 | 2 |
4. 제 2 정규화
1) 정의 (Whole Key Dependent)
- 두 개 이상으로 구성된 PK에서 발생한다.
- 2 정규형이기 위해서는, 모든 비식별자 속성(일반 컬럼)은 후보식별자 속성에 완전 함수적으로 종속되어야 한다.
2) 2정규화 방법
- 일반 속성 중에서, 후보 식별자 전체에 종속적이지 않은 속성을 찾아, 기본 엔터티에서 제거하고, 그 속성의 결정자를 주 식별자로 하는 새로운 상위 엔터티를 생성한다.
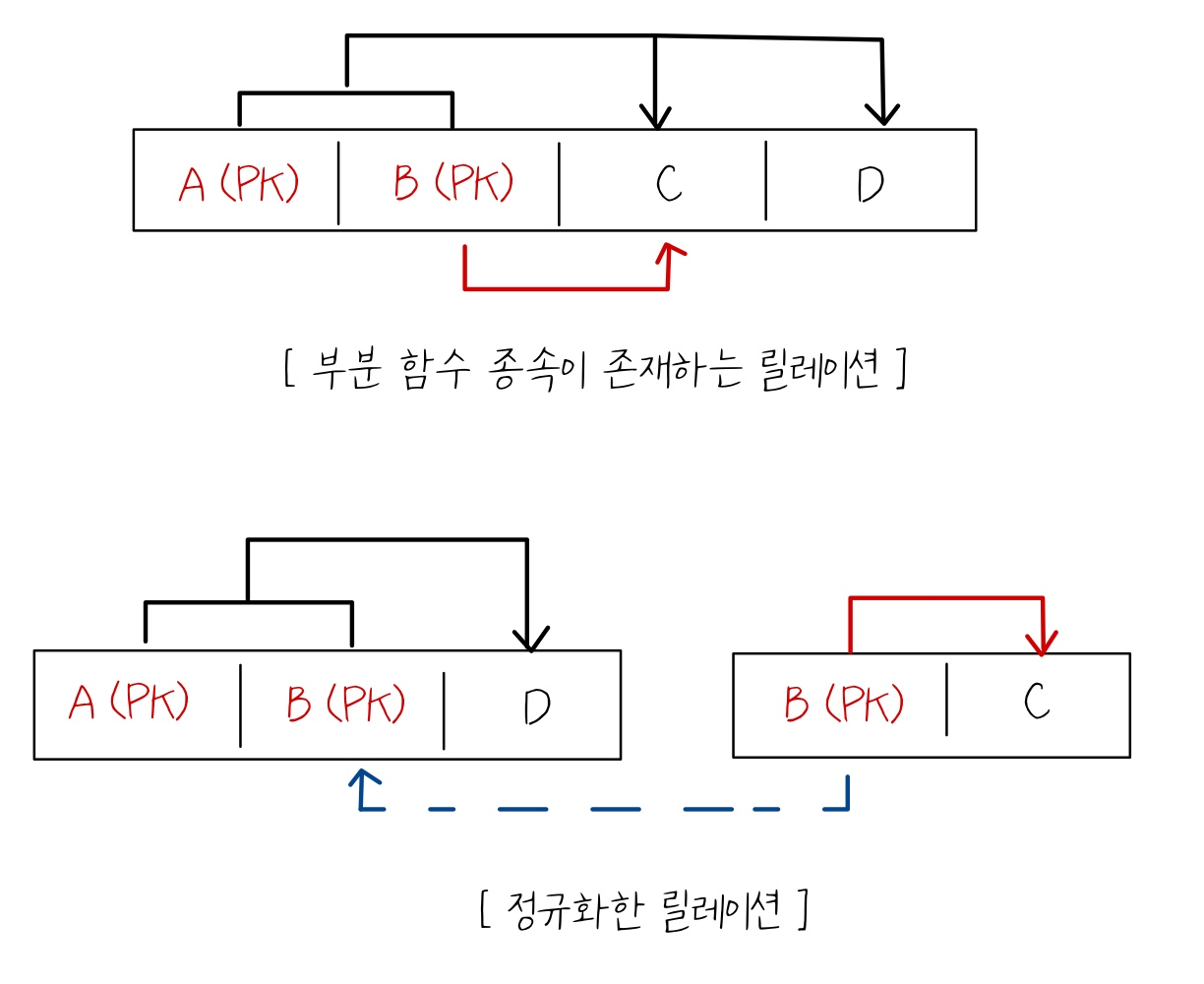
3) 실습 1
- 다음 릴레이션의 함수적 종속관계를 분석한 후, 2정규화를 수행하라
| 주문_상품 | |
| PK | 주문번호 |
| PK | 상품번호 |
| 상품명 | |
| 단가 | |
| 주문수량 | |
주문번호, 상품번호 -> 주문수량
상품번호 -> 상품명
상품번호 -> 단가
[ 2정규화 후 ]
| 주문_상품 | |
| PK | 주문번호 |
| PK + FK | 상품번호 |
| 주문수량 | |
| 상품 | |
| PK | 상품번호 |
| 상품명 | |
| 단가 | |
4) 실습 2
- 아래의 예시가, 2정규화를 위반하고 있는 것인가?
ex. 리그 소분류에서 리그대분류번호는, 리그 대분류의 PK를 참조하고 있는 FK이자, PK로서의 역할을 수행하고 있다.
그렇다면 여기서 리그소분류명은, 리그소분류번호만 알면 결정될 수 있으므로, 2정규화를 위반했다고 보아야하는가?
| 리그 대분류 | |
| PK | 리그대분류번호 |
| 리그대분류명 | |
| 리그 소분류 | |
| PK/FK | 리그대분류번호 |
| PK | 리그소분류번호 |
| 리그소분류명 | |
리그 소분류의 2정규화 위반 예시 : 소분류명이 소분류 PK 에만 영향을 받는 경우
| 대분류(PK + FK) | 소분류(PK) | 소분류명 |
| 10 | 01 | 북부리그 |
| 10 | 02 | 남부리그 |
| 20 | 03 | 웨스턴리그 |
| 20 | 04 | 이스턴리그 |
| 30 | 01 | 북부리그 |
| 30 | 02 | 남부리그 |
- 해결방안 1 : 대분류 + 소분류 PK에 모두 영향을 받는 컬럼명으로 변경
| 대분류(PK + FK) | 소분류(PK) | 리그분류명 |
| 10 | 01 | 1부 북부리그 |
| 10 | 02 | 1부 남부리그 |
| 20 | 03 | 2부 웨스턴리그 |
| 20 | 04 | 2부 이스턴리그 |
| 30 | 01 | 3부 북부리그 |
| 30 | 02 | 3부 남부리그 |
- 해결방안 2 : 대분류를 PK 해제하기. 즉 소분류만 PK로 설정 (대신 소분류의 내용을 대분류코드 + 소분류코드로 지정)
| 대분류 (FK) | 소분류(PK) | 리그분류명 |
| 10 | 1001 | 1부 북부리그 |
| 10 | 1002 | 1부 남부리그 |
| 20 | 2003 | 2부 웨스턴리그 |
| 20 | 2004 | 2부 이스턴리그 |
| 30 | 3001 | 3부 북부리그 |
| 30 | 3002 | 3부 남부리그 |
5. 제 3 정규화
1) 3정규화 정의
- 식별자가 아닌 일반 속성 간에는, 종속성이 존재하지 않는다.
- 3정규형의 대상이 되는 속성을, 이행 종속 속성이라고 한다.
- 즉 일반 속성간의 종속 관계를 분해하는 것을, 제 3 정규화라고 한다.
2) 3정규화 방법

3) 3정규화 예시
| 주문 | |
| PK | 주문번호 |
| 고객번호 | |
| 고객명 | |
| 주문일자 | |
| 배송요청일자 | |
PK가 아닌 고객번호가, 고객명에 영향을 주고 있다.
따라서 이를 분리해줄 필요가 있다.
[ 기준 테이블 ]
| 고객 | |
| PK | 고객번호 |
| 고객명 | |
[ 마스터테이블 ]
기준 테이블의 고객번호를 참조함. (FK)
| 주문 | |
| PK | 주문번호 |
| FK | 고객번호 |
| 주문일자 | |
| 배송요청일자 | |
6. BC 정규화
1) BC 정규화 정의
- 릴레이션에 존재하는 종속자는, 후보 식별자가 아니어야 한다.
2) BC 정규화 예시
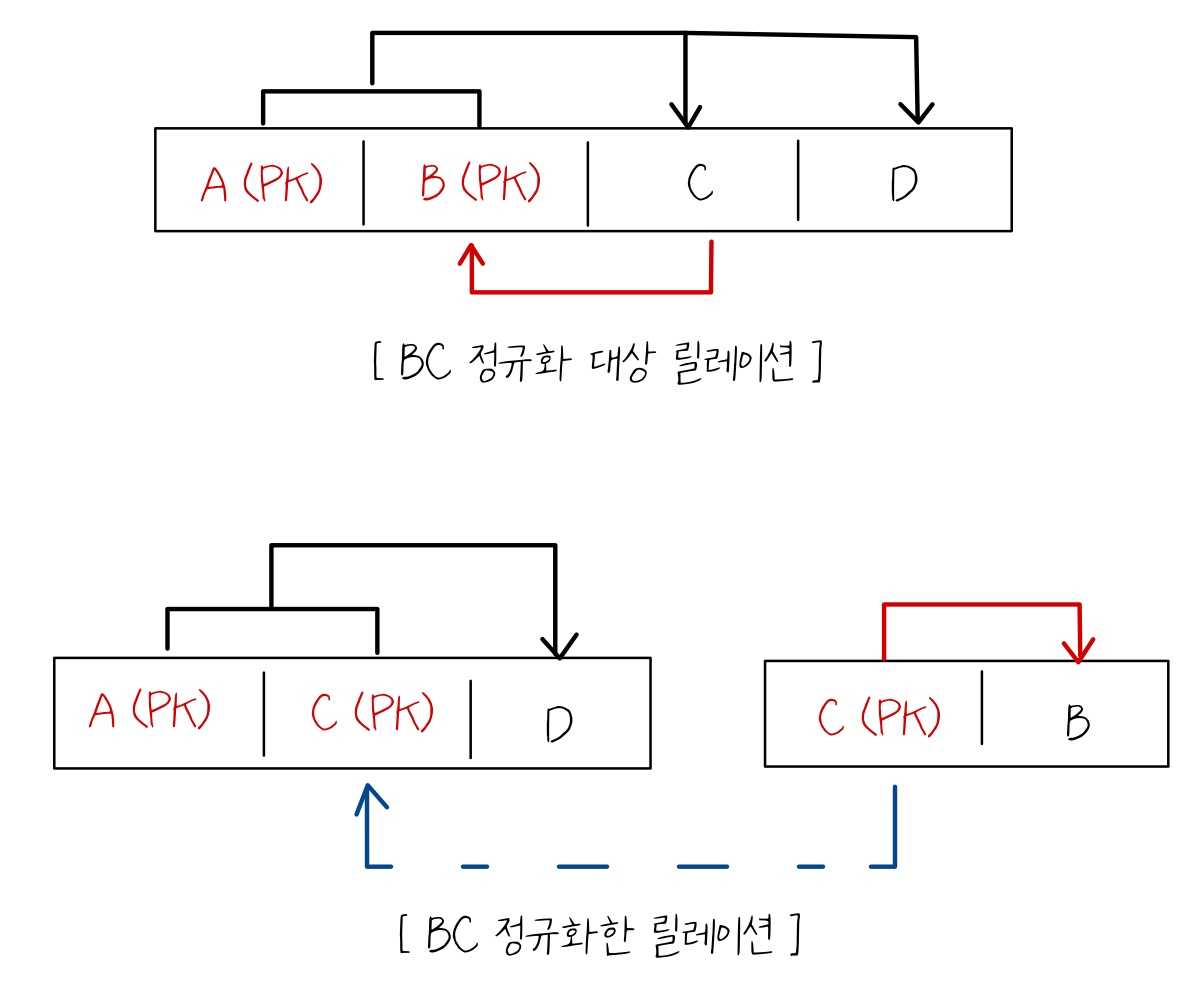
7. 역정규화
- 역정규화의 목적 : 효율
- 역정규화는 효율을 위해서 정규화된 결과의 일부를 수정하여, 중복을 일부로 만드는 것이다.
- 이유 : Join시 발생하는, 방대한 계산량을 해결하기 위해 사용

1) 역정규화 예시 1
| 고객 | |
| PK | 고객번호 |
| 고객명 | |
| 주문 | |
| PK | 주문번호 |
| FK | 고객번호 |
| 고객명 | |
| 주문일자 | |
| 배송요청일자 | |
2) 역정규화 예시 2
[ 마스터 테이블 ] 입출금 장부
| 년월 | 테이블명 | 통계 |
| 2019-12 | TBL_1912 | 입금: 100, 출금 70, 이익: 30 |
| 2020-01 | TBL_2001 | |
| ... | ... |
- 이 테이블을 보고, 필요한 월 테이블을 찾으러갈 수 있음. (달이 바뀌면 새 테이블이 생겨나기 때문)
- 마감된 테이블은 통계자료만 보는 경우가 주로 많음.
- 아마 현재 진행중인 장부만 주로 보려고 할 것임.
- 이와 같이 테이블이 무한대로 늘어난다면, 1:1 관계로 테이블을 쪼개서 튜닝하는 것이 필요하다.
* 해당 마스터 테이블은, 하단 테이블들과 1:1 관계
- 이처럼 관계 테이블의 설계에서는 반드시 역정규화를 고려하는 것이 필요하다.
* 역정규화로 힘들면, 테이블 분할로, 그조차도 힘든 빅데이터라면 데이터베이스 웨어하우스를 고려해야 한다.
dbo.TBL_1912 테이블 - 19년 12월 장부
| 날짜 | 적요 | 출금 | 입금 |
| 2019-11 | |||
| 2019-12 | |||
| ... |
dbo.TBL_2001 테이블 - 20년 1월 장부
| 날짜 | 적요 | 출금 | 입금 |
| 2019-12 | |||
| 2020-01 | |||
| ... |
| * 유의사항 - 아직 공부하고 있는 문과생 코린이가, 정리해서 남겨놓은 정리 및 필기노트입니다. - 정확하지 않거나, 틀린 점이 있을 수 있으니, 유의해서 봐주시면 감사하겠습니다. - 혹시 잘못된 점을 발견하셨다면, 댓글로 친절하게 남겨주시면 감사하겠습니다 :) |