[문과 코린이의 IT 기록장] RDBMS Modeling 실습 - User 테이블 설계, 시도 시군구 뷰 만들기, 시도 시군구 저장 프로시저 만들기, Company 뷰, 저장 프로시저 만들기, User 관련 사항 완성하기, Data Diagram ..

[문과 코린이의 IT 기록장] RDBMS Modeling 실습 - User 테이블 설계, 시도 시군구 뷰 만들기, 시도 시군구 저장 프로시저 만들기, Company 뷰, 저장 프로시저 만들기, User 관련 사항 완성하기, Data Diagram 테이블 배치 및 User 테이블 정보 분할, bit(boolean) 타입의 함정)
RDBMS Modeling 실습 - 인프런 | 강의
데이터베이스 설계 기초편에 이은 두 번째 강의입니다. 실전 프로젝트를 대상으로 처음부터 끝까지 만들어보는 실전 위주의 수업이며, 강의 내용을 모두 이해하고 나면 자유자재로 데이터베이
www.inflearn.com
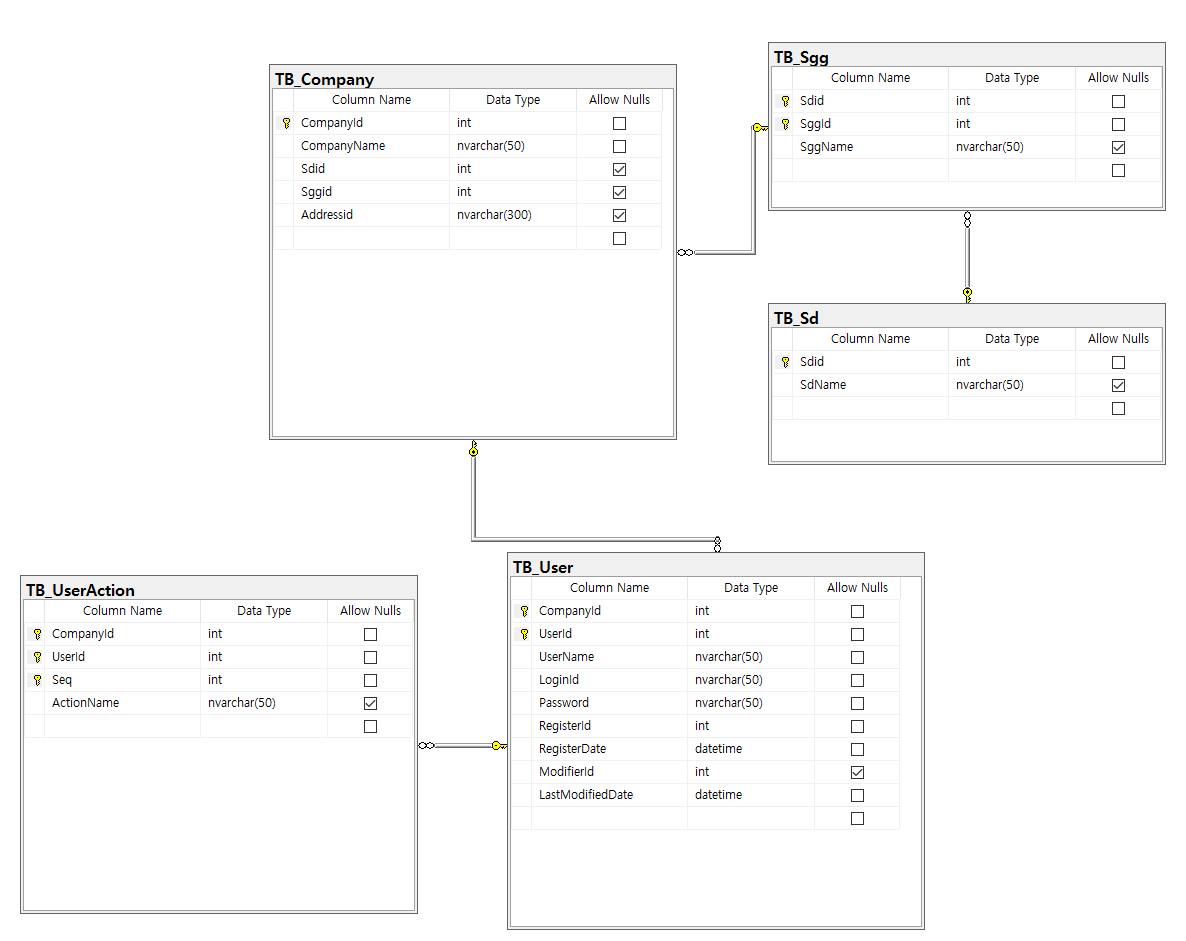
1. User 테이블 설계
* 일반적인 개발 흐름 : 화면 설계 -> DB 설계
* 그러나 하단 예시에서는, 화면 설계를 생략하고 DB 설계만 고려해보고자 한다.

[ User 테이블 설계 ]
- User테이블에서 UserID 컬럼은 자동증분을 적용한다.
: 이는 RDBMS가 테이블을 관리하기 위해서 정의하는 것으로, 어떤 것을 얻으려고 하는 정보가 아니다.
* 기준테이블에서는 자동증분을 쓰지 않는 것이 좋다.
- UserName 컬럼은 사람이 보기 위한 정보이다.
: 만약 컬럼이 굉장히 많아졌을 경우, DB의 값을 선택적으로 화면에 보여주는 경우가 있을텐데, 그 경우 UserName으로 구분해서 찾고자 하는 경우가 있을 것이다.
ex. select * from TB_User where Username = "김가나";
: 그렇다면 이 컬럼에는 인덱스(Index)를 설정해주는 것이 좋다.
* 기본적으로 어떤 값을 찾을 때, 처음부터 다 찾으려면 굉장히 많은 시간이 걸린다.
* 인덱스를 설정하면 서치(search)과정으로 간편하게 찾을 수 있다. (반반씩 잘라가면서 값을 찾아나가는 과정)
: 인덱스는 DB의 내용이 별로 없을 경우에는, 그다지 차이가 없지만, 내용이 굉장히 많아지게 되면 효율성을 발휘하게 된다.
: PK는 자동으로 Index 설정이 되지만, PK가 아닌 UserName 같은 경우 따로 설정해줘야 한다.
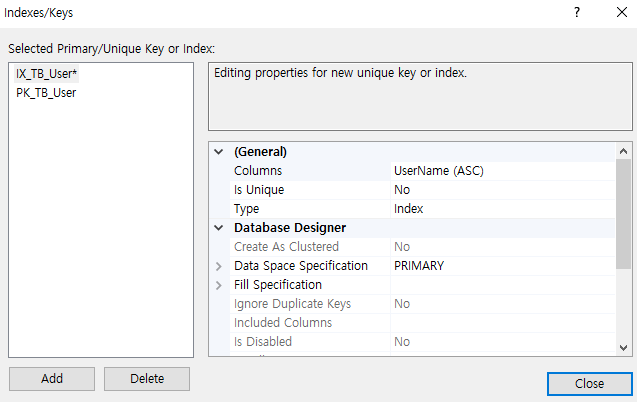
2. 시도 시군구 뷰 만들기
* cf ) nvarchar는 50 이하로 설정해놓지 않기.
1) TB_Company
[ Index 설정 ]
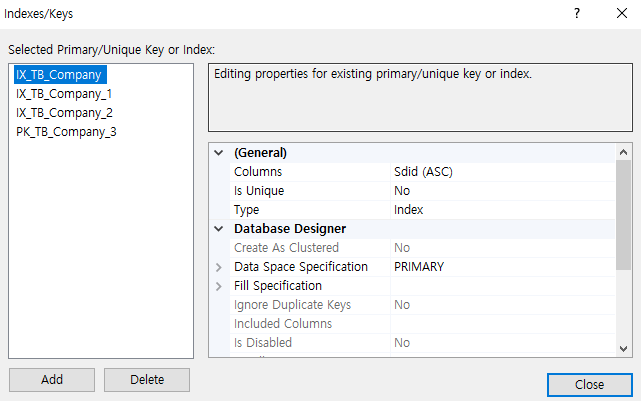
- PK인 CompanyId는 클러스터드 인덱스로 자동 설정된다.
* 클러스터드 인덱스는, 가장 효율적이고 최고의 성능을 보장해주는 인덱스이다.
- CompanyName, SdId, SggId 별도로 인덱스를 설정해주었다.
* 인덱스 설정으로 인해, 테이블 조회시 좀 더 쉽고 빠르게 찾을 수 있게 된다.
2) TB_Sd
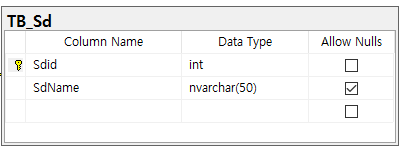
- TB_Company에서 SdId는 인덱스로서 역할을 하지만, TB_Sd 테이블에서는 인덱스가 따로 필요가 없다. 왜냐하면, TB_Sd 테이블에서 도메인은 광역시도 16개만 존재하기 때문에, 그리고 이는 변화할 가능서잉 크지 않기 때문에, 그냥 scan을 수행해도 별다른 시간의 차이가 존재하지 않기 때문이다.
- TB_Company와 같이 시간을 축으로 레코드가 늘어나는 테이블은 Index를 사용해야 하며, TB_Sd와 같이 시간을 축으로 레코드가 거의 멈춰있는 테이블은 기준테이블로 Index를 사용하지 않는 것이 효율적이다.
3) TB_Sgg
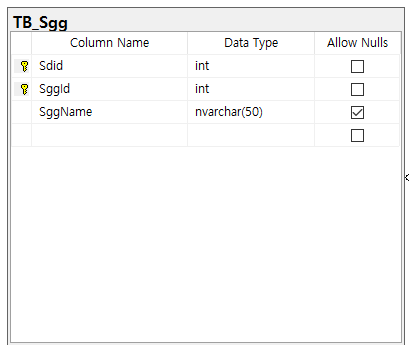
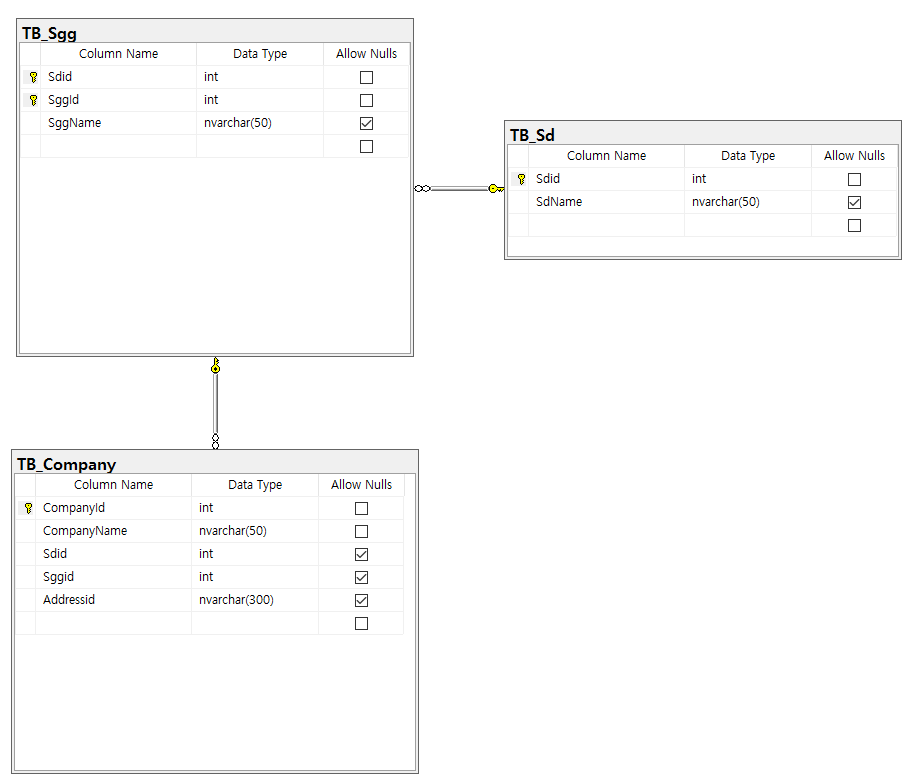
- Sgg 테이블에서 Sdid와 Sggid를 PK로 설정하여, 이 둘을 합쳤을 때 중복이 발생하지 않도록 보장한다.
- 이와 같이 원천적으로 중복을 막는 것을 보장한 후, TB_Company 테이블이 이 둘을 참조하는 형태로 관계를 구성한다.
* 각각 참조하는 모델도 존재할 수 있으나, 그러면 TB_Sgg 테이블에서의 중복 문제가 발생할 수 있다.
4) 시도 시군구 뷰
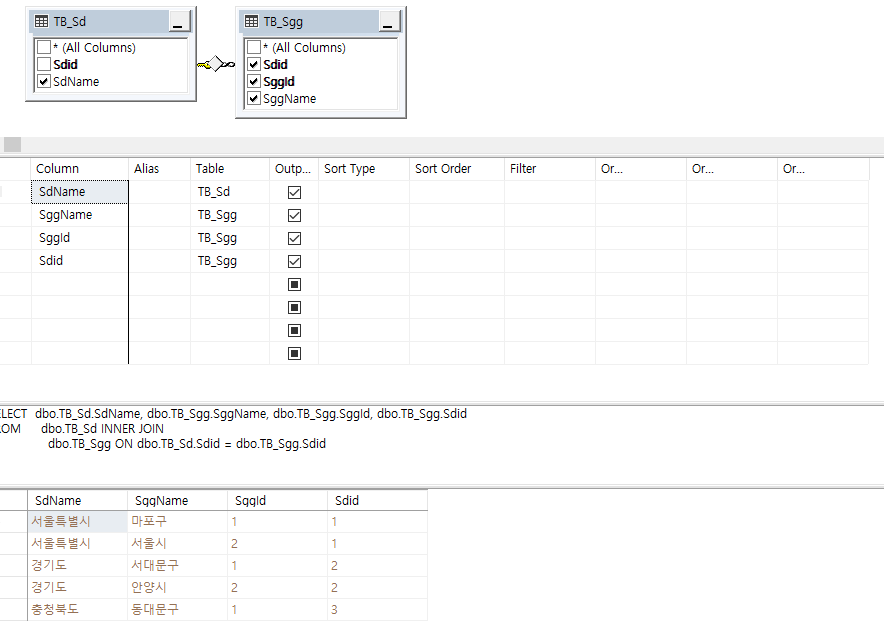
- 뷰를 설계할 때, 부모-자식 관계가 있는 테이블 간의 관계를 설계하는 경우에는, 자식을 중심으로 볼 수 있도록 설계한다.
- 따라서 위의 예시에서, TB_sgg의 컬럼들은 모두 선택하며, TB_sd의 컬럼은 이름만 선택한다.
* 선택한대로 select의 순서가 결정된다.
* 자식 테이블의 컬럼들 중, PK/FK는 반드시 선택해줘야 한다.
-- join문으로 호출할 경우
select * from TB_Sd
select * from TB_Sgg
select *
from TB_Sd a join TB_Sgg b on a.Sdid = b.Sdid
order by SdName, SggName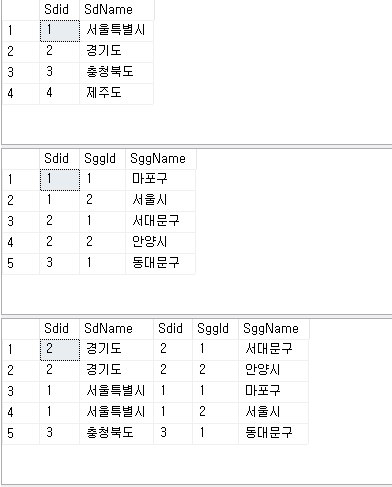
-- 뷰로 호출할 경우
-- 더 간편하게 사용 가능
select * from VW_Sgg
[ 뷰와 저장 프로시저의 차이 ]
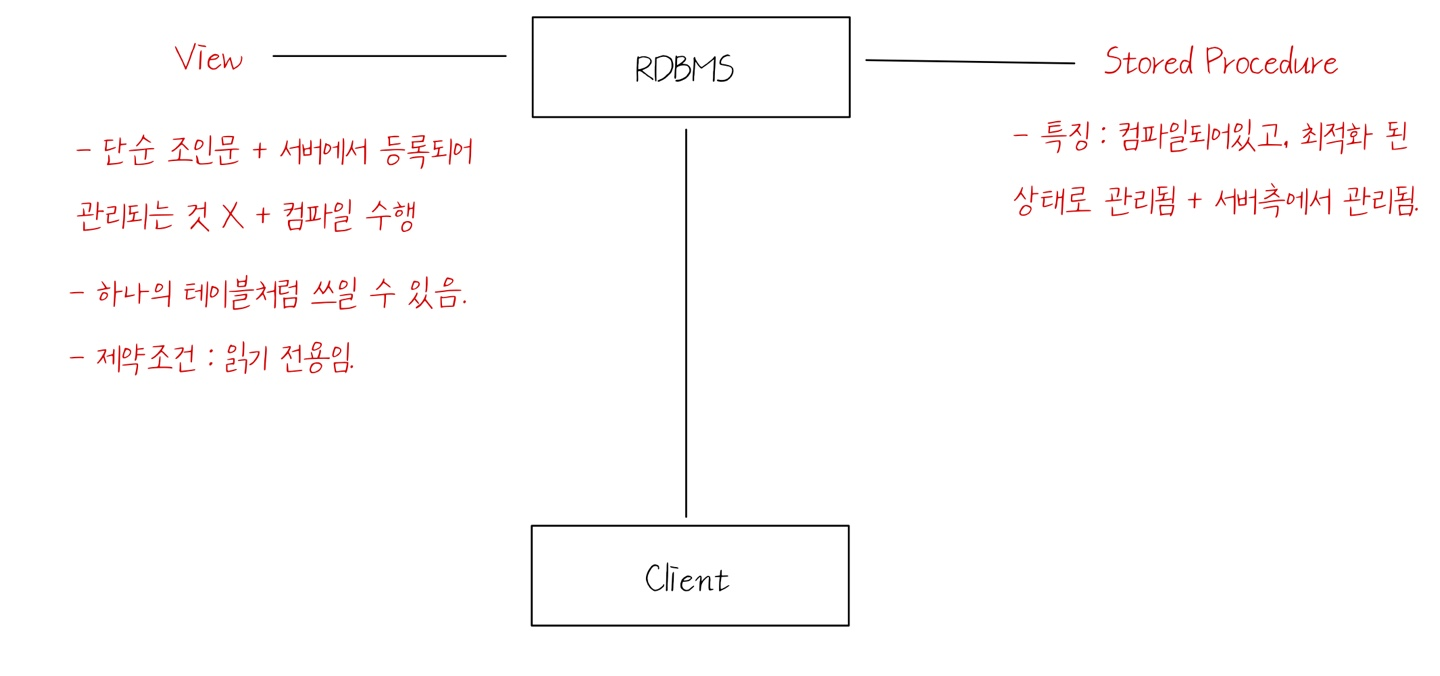
3. 시도 시군구 저장 프로시저 만들기
- 저장함수를 만들 때는 무조건 반드시 C/R/U/D를 만들어야함 (공식적인 것)
1) Sd 관련 저장 프로시저
[ SP_Sd_Add ]
CREATE PROCEDURE SP_Sd_Add
-- 레코드를 추가하는 것이므로, 모든 컬럼 내용이 파라미터로 들어와야함. (그러나 Sdid는 자동증분이므로 안들어와도 됨
@SdName nvarchar(50)
AS
INSERT INTO TB_Sd(SdName)
VALUES(@SdName)
-- TB_Sd테이블에 마지막으로 최종적으로 들어간 PK값을 반환해라
-- 프로그램에서 이것이 없으면 불편해짐
RETURN IDENT_CURRENT('TB_Sd')[ SP_Sd_UPDATE ]
CREATE PROCEDURE SP_Sd_UPDATE
@SdId int,
@SdName nvarchar(50)
AS
UPDATE TB_Sd
SET SdName = @SdName -- Sd의 Name값을 변경
where SdId = @SdId -- Sd의 Id값을 비교해서 조건에 맞는 것을 찾음.[ SP_Sd_Delete ]
CREATE PROCEDURE SP_Sd_Delete
@SdId int,
@SdName nvarchar(50)
AS
DELETE TB_Sd -- Sd 테이블에서
WHERE SdId = @SdId -- 해당 SdId값을 가지고 있는 레코들을 삭제한다.[ SP_Sd_GetById ]
CREATE PROCEDURE SP_Sd_GetById
-- Select
-- Pk에 해당되는 한 개의 레코드를 반환하는 프로시저는 무조건 존재해야 한다.
@SdId int
AS
SELECT *
FROM TB_Sd
WHERE SdId = @SdId -- 해당 Id를 가지고 있는 레코드들을 모두 조회한다.[ SP_Sd_GetAll ]
CREATE PROCEDURE SP_Sd_GetAll
@SdId int
AS
SELECT * -- 모두 출력
FROM TB_Sd
ORDER BY SdName
-- 두 개 이상의 레코드를 Select해야 하는 경우에 OrderBy는 필수조건임.2) Sgg 관련 저장 프로시저
[ SP_Sgg_Add ]
CREATE PROCEDURE [dbo].[SP_Sgg_Add]
@SdId nvarchar(50),
@SggName nvarchar(50)
AS
-- Sgg가 결정이 되어있지 않기 때문에 문제가 됨.
DECLARE @SggId int
SELECT @SggId = ISNULL(MAX(SggId), 0) + 1
FROM TB_Sgg
WHERE SdId = @SdId
INSERT INTO TB_Sgg(Sdid, SggId, SggName)
VALUES(@SdId, @SggId, @SggName)
RETURN @SggId[ SP_Sgg_Delete ]
CREATE PROCEDURE [dbo].[SP_Sgg_Delete]
@SdId int,
@SggId int
AS
DELETE TB_Sgg
WHERE SggId = @SggId[ SP_Sgg_Update ]
CREATE PROCEDURE [dbo].[SP_Sgg_Update]
@SdId int,
@SggId int,
@SggName nvarchar(50)
AS
UPDATE TB_Sgg
SET SggName = @SggName
WHERE SdId = @SdId AND SggId = @SggId[ SP_Sgg_GetBySd ]
CREATE PROCEDURE [dbo].[SP_Sgg_GetBySd]
@SdId int
AS
SELECT *
-- Sgg테이블을 조회했지만 SdName(시/군/구)가 나오지 않음.
-- 이를 해결하기 위해 join을 매번 해주기는 어려움.
-- 이 경우 VW를 테이블 대신 사용
FROM VW_Sgg
WHERE SdId = @SdId
ORDER BY SggName
-- Sgg같은 경우에는, GetById하면 Sd와 Sgg를 주면 됨.
-- 그런데 만약 서울시에 있는 시군구만 모두 다 달라고 하면, Sd만 주면서 쿼리를 보낼 것임
-- Sd는 최상위급이기 때문에, 즉 절대 마스터.
-- 즉, GetByParent()를 하면 SdId만, GetById()하면 SdId + SggId를, GetByAll()하면 SggName까지 모두 다 주는 것으로 Select문을 구성한다.exec SP_Sgg_GetBySd 1 -- SdId가 1인 레코드를 불러오기
[ SP_Sgg_GetById ]
CREATE PROCEDURE [dbo].[SP_Sgg_GetById]
@SdId int,
@SggId int
AS
SELECT *
FROM VW_Sgg
WHERE SdId = @SdId AND SggId = @SggId
-- 콤보박스를 선택하면, 이 프로시저를 알맞은 값으로 호출하도록 함.
-- GetByParent(Parent키가 있는 경우)는 GetAll을 잘 쓰지 않음.
-- 전국의 시/군/구를 다 가져와야 할 필요가 보통 잘 없음. (테이블을 뒤지는 의미가 없어지기 때문)exec SP_Sgg_getById 1,2 -- SdId가 1이고, SggId가 1인 레코드를 불러오기
4. Company 뷰, 저장 프로시저 만들기
1) Company 관련 뷰
(1) left join 사용 - Company 테이블의 Null값까지 모두 표현
SELECT a.CompanyId, a.CompanyName, a.Sdid, a.Sggid, a.Addressid, b.SdName, c.SggName
FROM dbo.TB_Company AS a LEFT OUTER JOIN
dbo.TB_Sd AS b ON a.Sdid = b.Sdid LEFT OUTER JOIN
dbo.TB_Sgg AS c ON a.Sdid = c.Sdid AND a.Sggid = c.SggId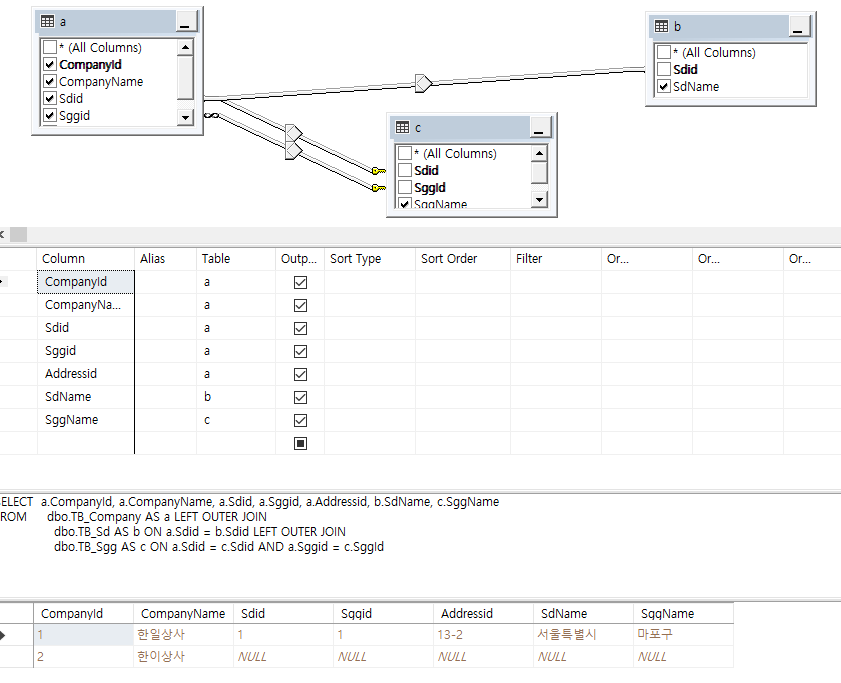
(2) inner join 사용 - Company 테이블의 Null 값 제외 표현
SELECT a.CompanyId, a.CompanyName, a.Sdid, a.Sggid, a.Addressid, d.SdName, c.SggName
FROM dbo.TB_Company AS a LEFT OUTER JOIN
dbo.TB_Sgg AS c ON a.Sdid = c.Sdid AND a.Sggid = c.SggId INNER JOIN
dbo.TB_Sd AS d ON c.Sdid = d.Sdid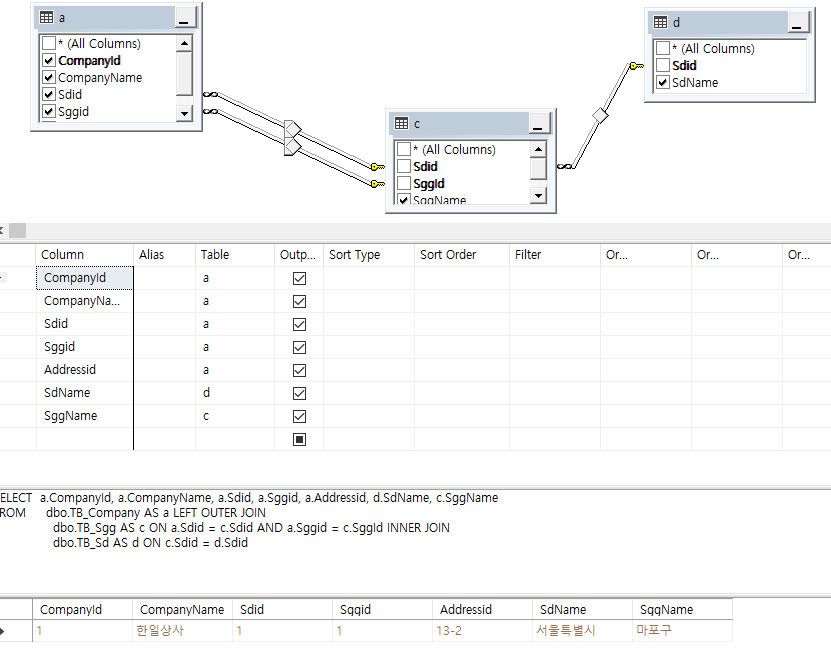
2) Company 관련 저장 프로시저
[ SP_Company_Add ]
CREATE PROCEDURE [dbo].[SP_Company_Add]
@CompanyName nvarchar(50),
@SdId int,
@Sggid int
AS
BEGIN
INSERT INTO TB_Company(CompanyName, Sdid, Sggid)
VALUES(@CompanyName, @SdId, @Sggid)
END
RETURN IDENT_CURRENT('TB_CompanyId')[ SP_Company_Update ]
CREATE PROCEDURE dbo.SP_Company_Update
@CompanyId int,
@CompanyName nvarchar(50),
@SdId int,
@Sggid int
-- CompanyName만 Update하고 싶다고, 따로 프로시저를 만들 필요는 없음.
-- 이 프로시저의 byte가 H/W에 큰 부담을 주지 않기 때문에, 그냥 이것을 사용해도 됨.
AS
BEGIN
UPDATE TB_Company
SET CompanyName = @CompanyName, Sdid = @SdId, Sggid = @Sggid
WHERE CompanyId = @CompanyId
END[ SP_Company_Delete ]
CREATE PROCEDURE dbo.SP_Company_Delete
@CompanyId int
AS
BEGIN
DELETE TB_Company
WHERE CompanyId = @CompanyId
END[ SP_Company_GetById ]
CREATE PROCEDURE dbo.SP_Company_GetById
@CompanyId int
-- CompanyId에 해당하는 정보를 출력해라 (Keyid이기 때문에 레코드는 하나만 나올것임)
AS
BEGIN
SELECT *
FROM TB_Company
WHERE CompanyId = @CompanyId
END[ SP_Company_GetByName ]
CREATE PROCEDURE dbo.SP_Company_GetByName
@CompanyName nvarchar(50)
-- CompanyName으로 자료를 찾을 가능성이 높기 때문에, 테이블 설계 시 이 컬럼을 인덱스로 만들어놓음.
AS
BEGIN
SELECT *
FROM VW_Company
WHERE CompanyName LIKE '%' + @CompanyName + '%';
END[ SP_Company_GetBySd ]
CREATE PROCEDURE dbo.SP_Company_GetBySd
@Sdid int
-- Sdid에 해당하는 내용들을 출력한다.
-- 다수의 레코드가 나오기 때문에, ORDER BY CompanyName으로 정렬해준다.
AS
BEGIN
SELECT *
FROM VW_Company
WHERE Sdid = @Sdid
ORDER BY CompanyName
END[ SP_Company_GetBySgg ]
CREATE PROCEDURE dbo.SP_Company_GetBySgg
@Sdid int,
@Sggid int
-- Sdid + Sggid에 동시에 해당하는 레코드들을 출력한다.
-- 다수의 레코드가 나올 가능성이 있으므로, ORDER BY CompanyName을 통해 정렬해준다.
AS
BEGIN
SELECT *
FROM VW_Company
WHERE Sdid = @Sdid AND Sggid = @Sggid
ORDER BY CompanyName
END[ SP_Company_GetBySdGroup ]
CREATE PROCEDURE dbo.SP_Company_GetBySdGroup
-- 통계정보
AS
BEGIN
SELECT Sdid, SdName, Count(*) as CompanyAmount
FROM VW_Company
GROUP BY Sdid, SdName
END
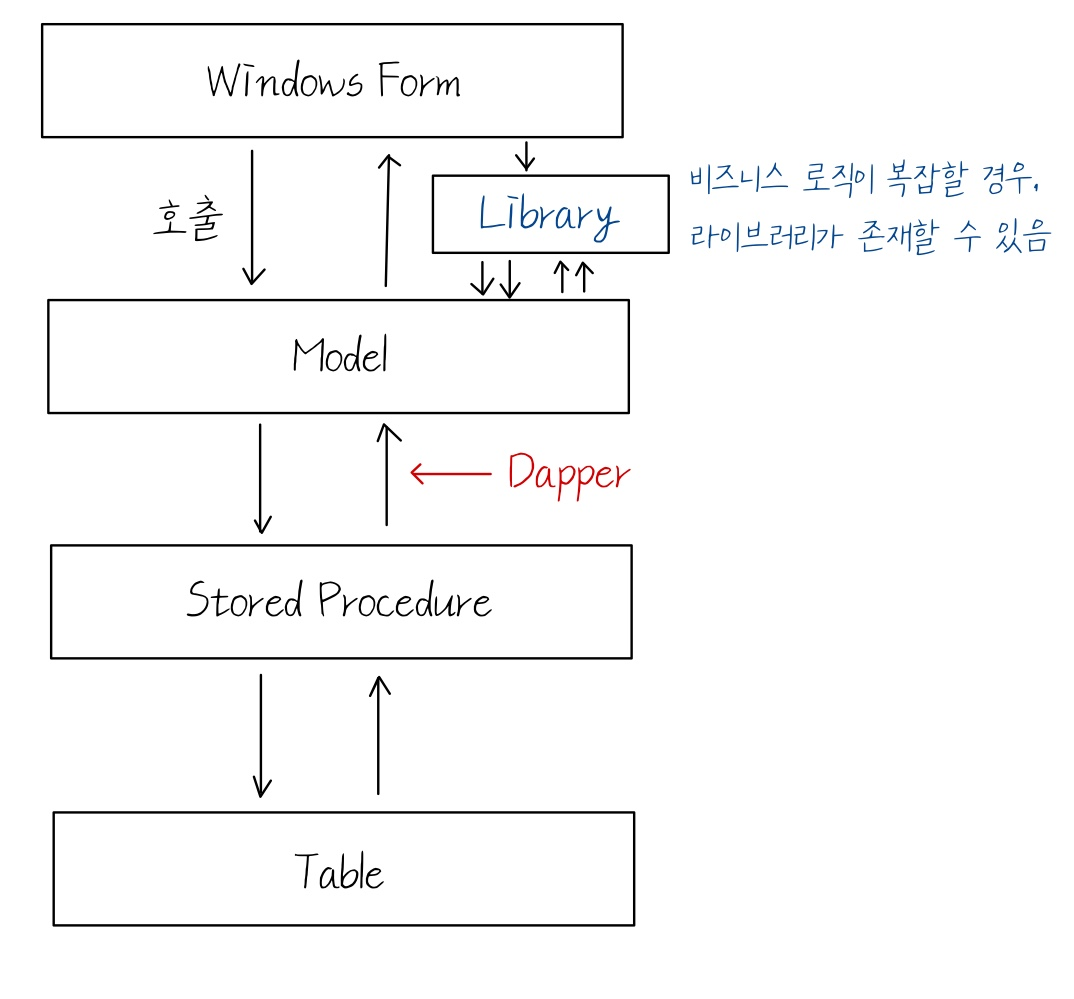
5. User 관련 사항 완성하기 1
1) 테이블
[ TB_User ]
- UserName Index설정 (O)
- LoginId : Unique (Yes) / Index 설정 (O)
- RegisterId : 해당 테이블에서 최초 레코드 등록 사용자 (LoginId에 존재하는 아이디만 입력될 수 있음)
- RegisterDate : 해당 테이블에서 최초 레코드 등록 일자
- ModifierId : 레코드 최종 수정자 // null 허용
- LastModifierDate : 레코드 최종 수정일자
* Date에는 기본값을, (getdate())로 적용시킴
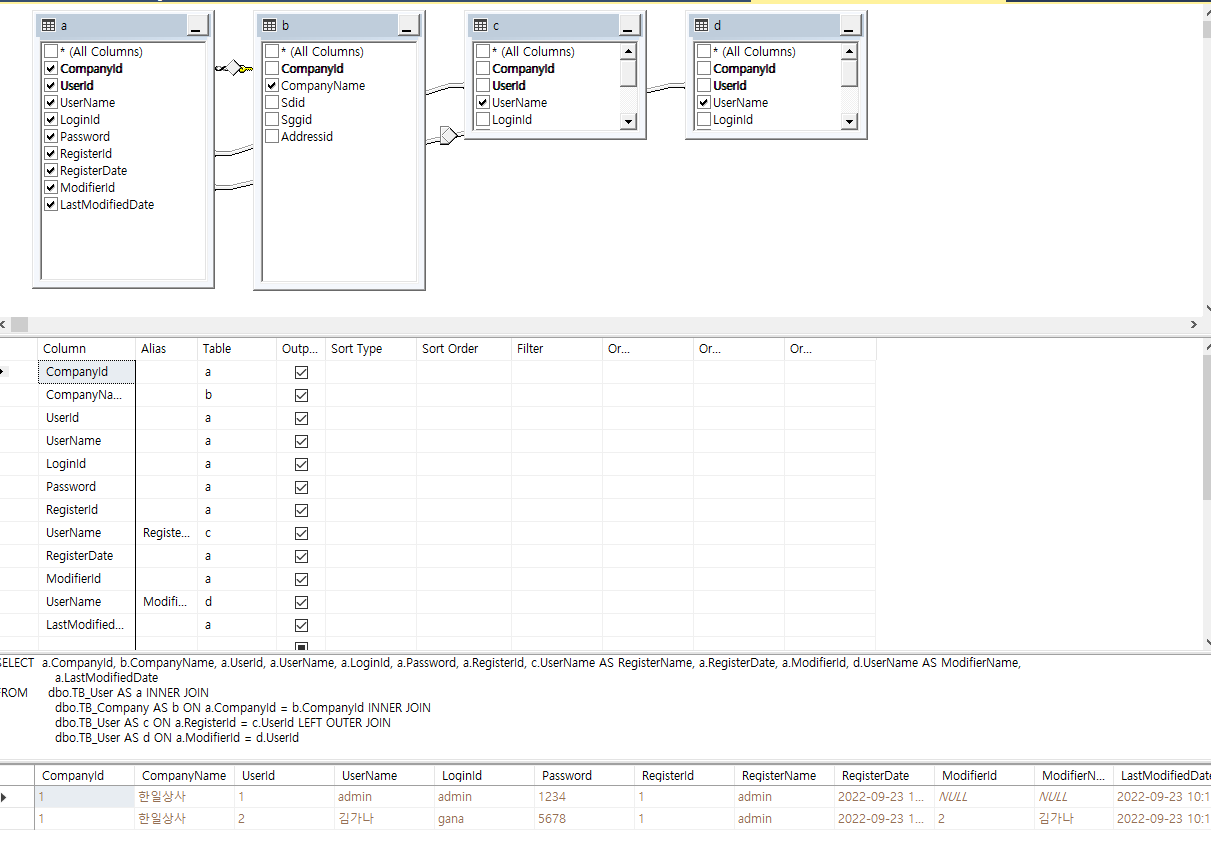
2) 뷰
[ VW_User ]
3) 프로시저
[ SP_User_Add ]
CREATE PROCEDURE SP_User_Add
@CompanyId int,
-- @UserId int, // UserId는 자동증분을 설정하지 않았지만 같은 기능을 해야하므로, AS 아래 @UserId를 선언하면서 자동 동작하도록 설정해준다.
@UserName nvarchar(50),
@LoginId nvarchar(50),
@Password nvarchar(50),
@RegisterId int
-- @RegisterDate datetime, // Date는 시스템에서 자동으로 가져오므로 불러올 필요 X
-- @ModifierId int, // 맨 처음 User를 추가할 적에는, Modifier는 존재하지 않으므로, 불러올 필요 X
-- @LastModifiedDate datetime
AS
-- UserId 자동 설정
DECLARE @UserId int
SELECT @USERID = ISNULL(MAX(UserId),0) + 1
FROM TB_User
WHERE CompanyId = @CompanyId -- 회사마다 UserId는 다르게 설정할 것이므로
BEGIN
INSERT INTO TB_User(CompanyId, UserId, UserName, LoginId, Password, RegisterId)
VALUES(@CompanyId, @UserId, @UserName, @LoginId, @Password, @RegisterId)
END
GO[ SP_User_GetByName ]
CREATE PROCEDURE SP_User_GetByName
@CompanyId int, -- UserName을 기준으로 찾을 때, CompanyId(회사명) 또한 가져와야함. // 이를 설정하지 않으면, 다른 회사 정보가 같이 나옴
@UserName nvarchar(50)
AS
BEGIN
SELECT *
FROM TB_User
WHERE CompanyId = @CompanyId AND UserName like '%' + @UserName + '%'
ORDER BY UserName
-- 사용자들 입장에서는 하나의 DB를 자신의 회사만 쓰고 있다고 생각한다.
-- 그런데 사실 DB에는 다양한 회사의 정보들이 모두 모여있는 것이 일반적이다.
-- 따라서 만약 CompanyId에 따라 불러오는 조건을 정의해두지 않으면, 여러 회사의 정보들이 섞여서 문제가 발생한다.
END
GO[ SP_User_GetALL ]
CREATE PROCEDURE SP_User_GetALL
@CompanyId int
AS
BEGIN
SELECT *
FROM TB_User
WHERE CompanyId = @CompanyId
ORDER BY UserName
-- 사용자들 입장에서는 하나의 DB를 자신의 회사만 쓰고 있다고 생각한다.
-- 그런데 사실 DB에는 다양한 회사의 정보들이 모두 모여있는 것이 일반적이다.
-- 따라서 만약 CompanyId에 따라 불러오는 조건을 정의해두지 않으면, 여러 회사의 정보들이 섞여서 문제가 발생한다.
END
GO[ SP_User_Update ]
CREATE PROCEDURE SP_User_Update
@CompanyId int,
@UserId int,
@UserName nvarchar(50),
@LoginId varchar(50),
@Password varchar(50),
@ModifierId int,
@LastModifiedDate datetime
AS
BEGIN
UPDATE TB_User
SET
UserName = @UserName,
LoginId = @LoginId,
Password = @Password,
ModifierId = @ModifierId,
LastModifiedDate = @LastModifiedDate
WHERE
CompanyId = @CompanyId AND
UserId = @UserId
END
GO4) 조인
[ Join (Inner Join) ]
select *
from vw_user a join tb_UserAction b on a.CompanyId = b.CompanyId and a.UserId = b.UserId;
-- TB_UserAction에 값이 존재할 때만 레코드가 출력된다.
[ left outer Join ]
select *
from vw_user a left outer join tb_UserAction b on a.CompanyId = b.CompanyId and a.UserId = b.UserId;
-- TB_UserAction에 값치 존재하지 않더라도, vw_User의 레코드를 중심으로, null로 입력되어 출력된다.
5) User 레코드 Delete
User 테이블에서 특정 살용자의 정보를 삭제하고자 할 때, 만약 UserAction 테이블에 관련 정보가 존재하는 경우 삭제가 불가능하다. 왜냐하면, 부모가 존재하지 않는 자식이 요소들이 만들어지기 때문이다.
delete TB_User where CompanyId = 1 and UserId=3;그러나, UserAction 테이블에 관련 정보가 없다면, User 테이블에서 정보를 삭제할 수 있다.
-- 삭제 및 업데이트를 임의로 해보고 싶을 경우 이렇게 해보기
-- begin transaction부터 select 까지 블록해서 실행한 후,
begin transaction
delete TB_User where CompanyId = 1 and UserId=2;
select * from TB_User
-- rollback transaction 수행
rollback transaction
이와 같이 User 테이블에서 ID탈퇴와 같이 정보를 삭제하고 싶은 경우가 있을 것이다. 이 경우 해결 방법은 2가지가 있다.
a. User 테이블에 사용여부 컬럼을 하나 더 추가해서 지정해준다. - isDeleted (기본값 : 0)
* 자식 요소가 없으면 그냥 Delete하도록 구성하고, 자식요소가 존재하면 try-catch 예외처리문을 통해, isDeleted를 설정하도록 프로그램을 구성할 수 있다.
b. 해당 User 테이블과 관련된 레코드를 모두 삭제해준다.
* 그런데 관리상, 과거의 자료가 필요한 경우가 있으므로, 일반적으로 모든 탈퇴 이용자 내역들을 삭제하지 않는다.
* 만약 연관된 모든 정보를 삭제할 필요가 있을 경우, 트랜잭션으로 직접 코드를 작성해 실행시키거나, 아니면 데이터 다이어그램의 삭제 규칙 중 casecade를 설정해, 연쇄 삭제가 이루어지도록 한다.
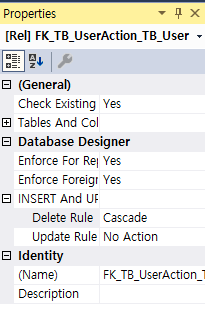
주의 ) Casecade는 관계가 존재하는 아무 곳에나 걸면 안된다. 모든 관계에 이것을 적용시켰을 경우, 하나의 레코들르 삭제할 때, 관련된 나머지 레코드들도 모두 사라질 수 있다. 따라서 비즈니스 데이터와 같은 중요한 기록들 (ex. UserAction)의 경우에는 삭제 규칙을 지정하지 않는 주의가 필요하다.
6. User 테이블 완성하기 2
1) 테이블
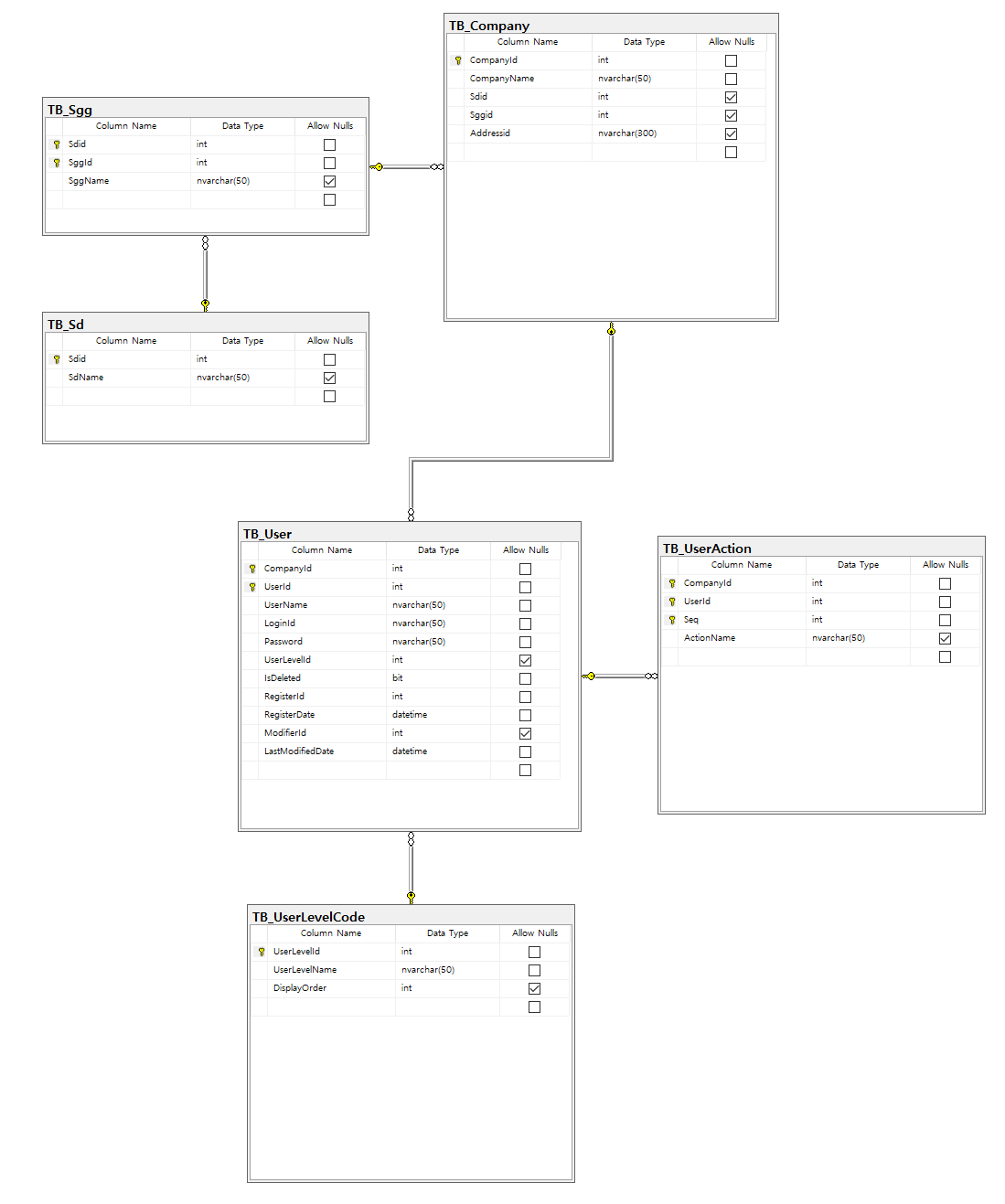
[ TB_User ]
- UserLevelId : 사용자 레벨에 따라서 권한을 부여할 수 있는 컬럼
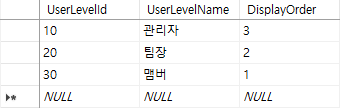
[ TB_UserLevelCode ] // 기준 테이블
- UserLevelId : 사용자 레벨 코드(숫자)
- UserLevelName : 사용자 레벨 명칭
- DisplayOrder // null허용 (사용자들이 직접 커스터마이징 해서 쓸 수 있도록)
ps. 기준 테이블은 일반적으로 자동 증분을 주지 않는다.
- 여기서 UserLevelId는 PK의 역할을 하는 것과 더불어, 어떤 코드의 의미를 같이 가지고 있다.
- 아래와 같이 10번대는 관리자, 20번대는 팀장, 30번대는 맴버를 나타내고자 한다.
- 이렇게 수동으로 10 / 20 / 30으로 입력해주는 이유는, 예를 들어 나중에 관리자가 세부적으로 분류될 수 있을 가능성이 존재할 경우, 즉 나중에 11번 - 보조관리자 / 12번 - 부관리자 등 직책이 늘어날 가능성이 있는 경우를 위한 것이다.
- 또한 만약 자동증분을 해놓으면, 어떤 직책이 사라졌을 때 숫자가 하나씩 당겨지므로, 값이 변경될 우려가 있기 때문에, 프로그래밍시 활용하기 어렵다.
- 프로그램과의 연동 방법은 아래와 같다.
namespace Globals
{
public enum UserLevelEnum
{
관리자 = 10,
팀장 = 20,
맴버 = 30
}
}public class UserModel
{
public UserLevelEnum UserLevelId { get; set; }
}public void Form1_Shown(object sender, EventArgs e)
{
UserModel um = new UserModel();
um.UserLevelId = UserLevelEnum.맴버;
// UserLevelENum.맴버 = 30 이와 같음
// 이런 형태로 사용함
}- 이와 같이 DB설계를 하는 사람은, Enum부분까지 고려하는 것이 필요하다.
2) 뷰 수정
[ VW_User ]
SELECT a.CompanyId, b.CompanyName, a.UserId, a.UserName, a.LoginId, a.Password, a.RegisterId, c.UserName AS RegisterName, a.RegisterDate, a.ModifierId, d.UserName AS ModifierName, a.LastModifiedDate, a.UserLevelId, a.IsDeleted
FROM dbo.TB_User AS a INNER JOIN
dbo.TB_Company AS b ON a.CompanyId = b.CompanyId INNER JOIN
dbo.TB_User AS c ON a.RegisterId = c.UserId LEFT OUTER JOIN
dbo.TB_User AS d ON a.ModifierId = d.UserId INNER JOIN
dbo.TB_UserLevelCode AS e ON a.UserLevelId = e.UserLevelId
// User Level은 inner join문으로, 둘 다 해당되는 경우만 표현하도록 할 것3) 프로시저 수정
- 테이블 컬럼이 변경되는 경우, View만 고치면 Select 관련 프로시저들은 모두 자동 변경된다. (Select는 테이블 대신 뷰를 기준으로 값을 얻어오기 때문에)
- 따라서 테이블 컬럼 변경 시, 프로시저는 Add와 Update만 변경하면 된다.
[ SP_User_Add ]
ALTER PROCEDURE [dbo].[SP_User_Add]
@CompanyId int,
-- @UserId int, // UserId는 자동증분을 설정하지 않았지만 같은 기능을 해야하므로, AS 아래 @UserId를 선언하면서 자동 동작하도록 설정해준다.
@UserName nvarchar(50),
@LoginId nvarchar(50),
@Password nvarchar(50),
@UserLevelId int,
@IsDeleted bit,
@RegisterId int
-- @RegisterDate datetime, // Date는 시스템에서 자동으로 가져오므로 불러올 필요 X
-- @ModifierId int, // 맨 처음 User를 추가할 적에는, Modifier는 존재하지 않으므로, 불러올 필요 X
-- @LastModifiedDate datetime
AS
-- UserId 자동 설정
DECLARE @UserId int
SELECT @USERID = ISNULL(MAX(UserId),0) + 1
FROM TB_User
WHERE CompanyId = @CompanyId -- 회사마다 UserId는 다르게 설정할 것이므로
BEGIN
INSERT INTO TB_User(CompanyId, UserId, UserName, LoginId, Password, UserLevelId, IsDeleted, RegisterId)
VALUES(@CompanyId, @UserId, @UserName, @LoginId, @Password, @UserLevelId, @IsDeleted, @RegisterId)
END
[ SP_User_Update ]
ALTER PROCEDURE [dbo].[SP_User_Update]
@CompanyId int,
@UserId int,
@UserName nvarchar(50),
@LoginId varchar(50),
@Password varchar(50),
@UserLevelId int,
@IsDeleted bit,
@ModifierId int,
@LastModifiedDate datetime
AS
BEGIN
UPDATE TB_User
SET
UserName = @UserName,
LoginId = @LoginId,
Password = @Password,
UserLevelId = @UserLevelId,
IsDeleted = @IsDeleted,
ModifierId = @ModifierId,
LastModifiedDate = @LastModifiedDate
WHERE
CompanyId = @CompanyId AND
UserId = @UserId
END7. Data Diagram 테이블 배치 및 User 테이블 정보 분할
1) Data Diagram 테이블 배치 규칙
: 가장 상위 테이블을 가장 오른쪽에 놓고 시작한다.
: 해당 테이블과 관련된 자식 테이블들은 그 왼쪽에 배치하며, 부모 테이블들은 오른족에 배치한다.
: 해당 테이블의 아래에 있는 테이블들은, 상단 테이블의 확장판이라는 의미이다.
* 열쇠를 받는쪽이 부모 테이블, 무한대 표시가 자식 테이블 (1:M 관계시)
* 양쪽 모두 열쇠를 받고 있다면 1:1 관계를 구성하는 것이다.
* 1:1 관계를 형성할 경우에는, 상위 테이블(PK)에서 세부 항목쪽(FK)으로 끌어가서 관계를 만들어야 한다. 그렇지 않으면, 세부 항목에서 먼저 값을 입력해야 상위 테이블에 입력이 가능한 이상한 형태가 만들어지게 된다.
2) User 테이블 정보 분할
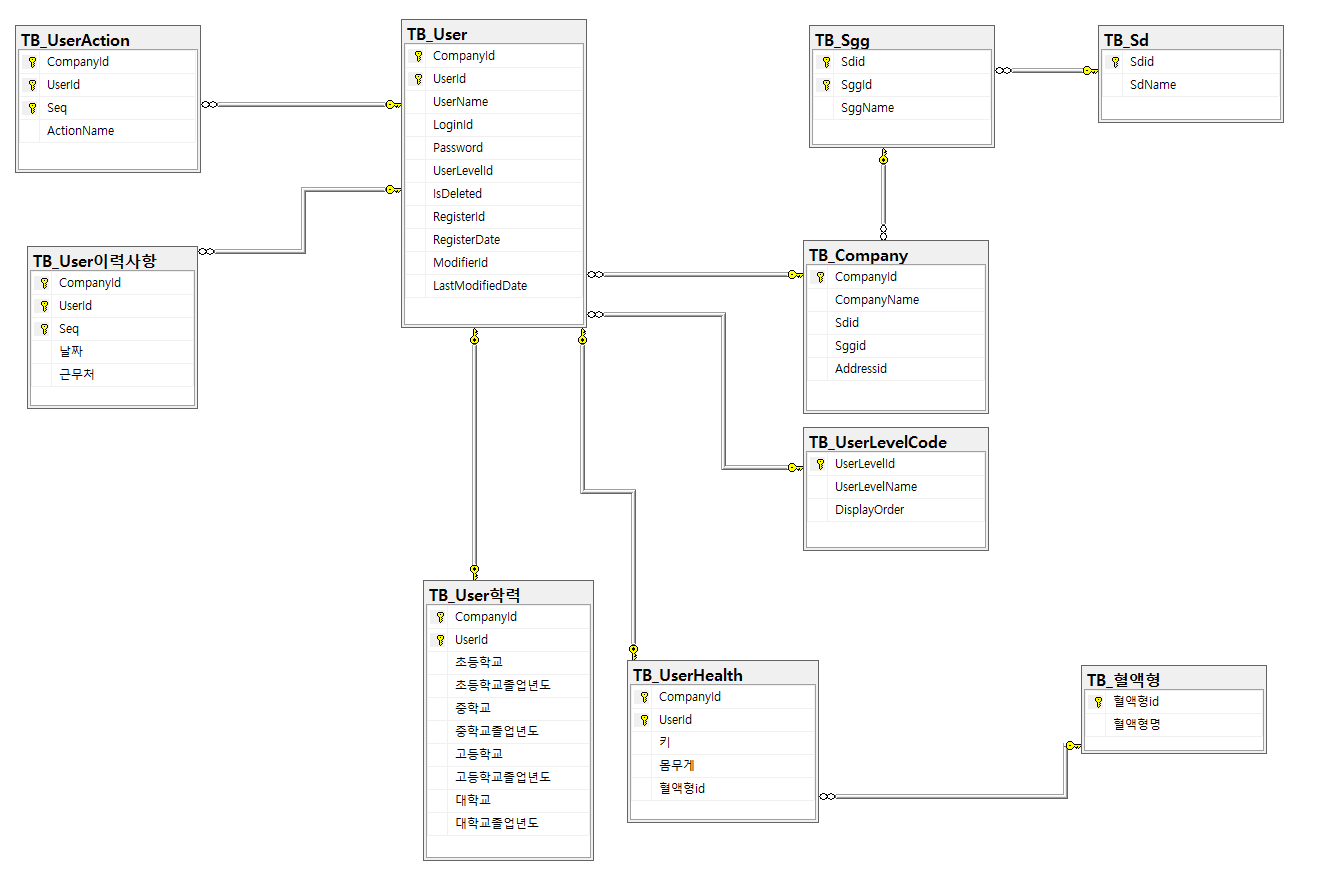
- 만약 회사가 너무 큰 곳이라, User 아이디가 굉장히 많을 경우, 그리고 수집해야 하는 User 정보도 굉장히 방대한 경우, User 테이블을 분할하는 것이 필요하다.
- 맨 처음 접속할 때 필요한 로그인 관련 정보들 제외하고는, 1:1혹은 1:M 관계를 통해 User 정보들을 분할한다.
* 해당 테이블들은, User 테이블의 PK 컬럼을 항상 추가해서 관계를 형성한다.
cf. 도메인이 이미 정해져있고, 거의 불변일 것이라고 판단되는 경우만 기준 테이블을 생성한다. ex. TB_혈액형
- 이 경우만 프로그래밍시 enum으로 지정 가능하다.
- 절대 마스터 테이블이더라도 기준 테이블이 아니라면, enum을 사용하지 않아야 한다. ex. TB_Sd
- 위의 데이터 다이어그램에서, TB_User이력사항은 1:M의 관계를 나타내고 있다. 왜냐하면 근무처가 하나가 아니라 여러개가 가능할 수 있기 때문이다. 즉 CompanyId / UserId가 중복될 수 있다는 것이며, 이를 해결하기 위해 Seq를 추가해 함께 PK로 구성해준다.
- 반대로 TB_User학력은 1:1관계를 가지고 있다. 가능한 학교의 Case를 모두 표현해주고 있기 때문이다. 만약 이를 1:M관계로 구성하려면, '학교 / 학교 졸업년도' 이러한 형식으로 컬럼을 만들어야 할 것이다.
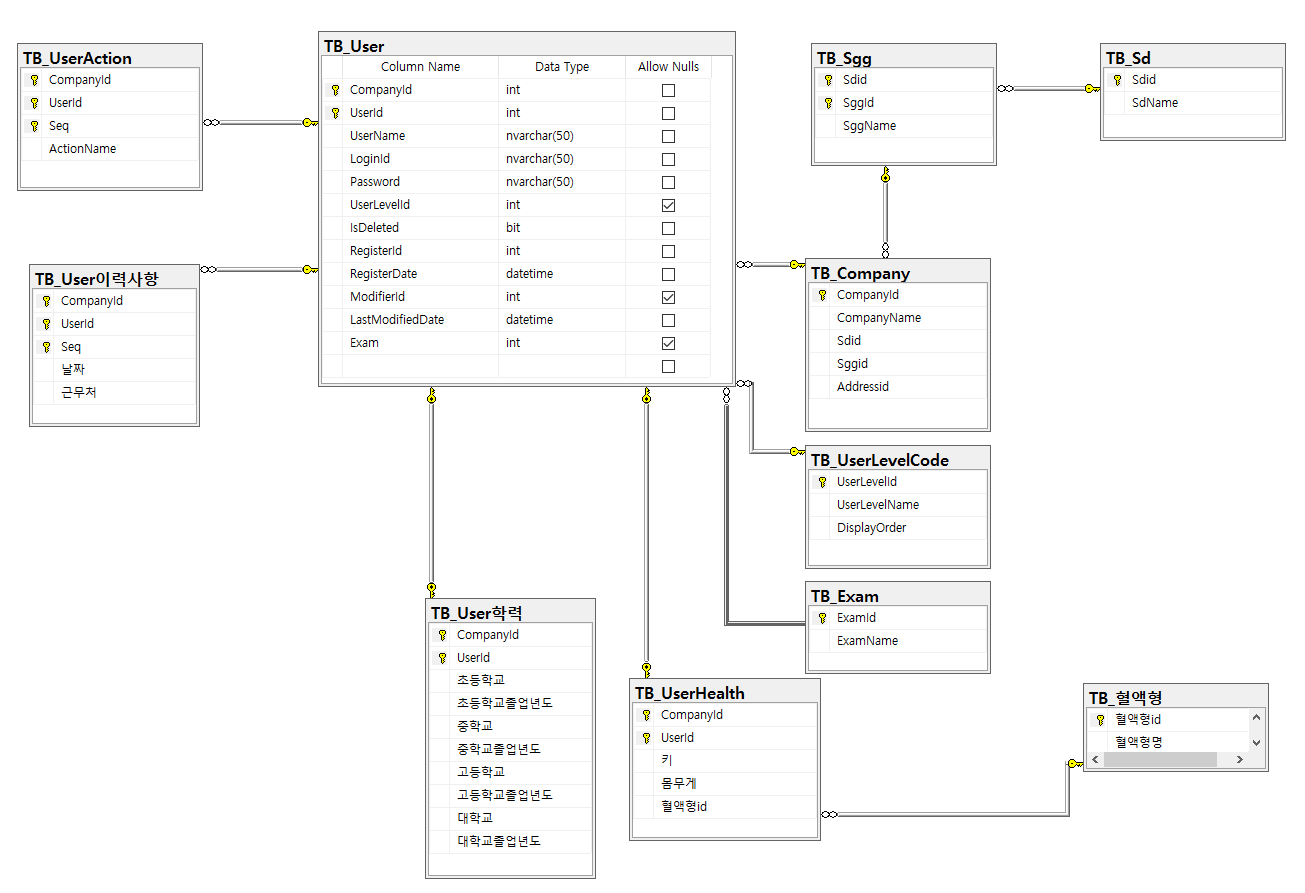
8. bit(boolean) 타입의 함정
- Exam의 경우 나올 수 있는 값의 결과 : 합격 / 불합격 / 미응시
- 만약 Exam을 bit로 표현하면, 합격(True) / 불합격(False) / 미응시(Null)로 표현될 것이다.
- 그런데 이를 프로그래밍에서 활용할 때, 불합격(Fasle)과 미응시(Null)가 구별되지 않는 문제가 발생한다.
ex.체크박스 활용
- 따라서 Exam같은 경우는 bit가 아닌, int타입을 사용해야 하며, 이에 대한 기준테이블을 만들어서 1:M관계를 형성시켜주는 것이 더 올바른 DB구성방식이다.
| * 유의사항 - 아직 공부하고 있는 문과생 코린이가, 정리해서 남겨놓은 정리 및 필기노트입니다. - 정확하지 않거나, 틀린 점이 있을 수 있으니, 유의해서 봐주시면 감사하겠습니다. - 혹시 잘못된 점을 발견하셨다면, 댓글로 친절하게 남겨주시면 감사하겠습니다 :) |