
1. 단일 사이클 구현의 문제점
: 4.4에서 보았던 방식은, 한 명령어를 데이터패스를 통해 실행하는 동안에, 다음 명령어는 앞 명령어가 실행이 끝날때까지 기다리게 된다.
: 이는 클럭사이클 시간을 너무 길어지게 해, 전체 성능을 떨어지게 한다.
2. 파이프라이닝
1) 파이프라이닝의 정의 및 이점
- 정의 : 여러 명령어가 중첩되어 실행되는 기술. (병렬성을 이용)
* 각 명령어의 실행시간을 개선시키지는 못하지만, 처리량을 개선한다.
- n(실행 명령어 개수), T(시간), k(파이프라인 개수)
파이프라이닝을 하지 않았을 때, 걸리는 시간 : TS = n x T
파이프라이닝을 했을 때, 걸리는 시간 : TP = (n+k-1) x T/k
SpeedUp : SP = TS/TP ≅ k (n이 상당히 커지면 0에 수렴하기 때문.
ex) n = 100, T = 10
a. TS = 100 x 10 = 1000sec
b. k=5, TP = (100+5-1) x (10/5) = 208sec
c. k = 10, TP = (100+10-1) x (10/10) = 109sec
- 더 많이 파이프라이닝할수록, 초가 줄어드는 것을 볼 수 있음.
2) Single Cycle vs Multiple Cycle vs Pipeline

- 파이프라인 SpeedUp을 위해, 많이 같은 길이로 나누는 것이 필요함.
3) 요약

3. 명령어 실행의 5단계 (MIPS)
- 명령어 실행을 파이프라이닝 한 프로세서에도 같은 원리가 적용된다.
(1) 명령어 메모리에서 명령어를 가져온다. (IF = Instruction Fetch)
(2) 명령어를 해독하는 동시에 레지스터를 읽는다. - Mips 명령어는 형식이 규칙적이므로, 읽기와 해독이 동시에 일어날 수 있다. (ID = Instruction Decode, and Register file read)
(3) 연산 수행 또는 주소 계산을 수행한다. (EX = Execution and address calculation)
(4) 데이터 메모리에 있는 피연산자에 접근한다. (MEM = Data Memory access)
(5) 결과 값을 레지스터에 쓴다. (WB = Write Back)
ex ) 단일사이클 vs 파이프라인 성능
- 이 강에서는 8개의 명령어만 관심을 가진다. (lw, sw, add, sub, AND, OR, slt, beq)
: 주요 기능 유닛의 동작시간은 메모리 접근 200ps, ALU연산 200ps, 레지스터 파일 읽기나 쓰기 100ps
- 단일 사이클 구현에서는 모든 명령어가 한 클럭 사이클이 걸린다. 따라서, 가장 느린 명령어를 수용할 수 있을 만큼 클럭사이클이 길어야한다.
[ 각 기능 유닛 수행시간과 수행명령어 예시 ]
| 명령어 종류 | Instruction Fetch | Register Read | ALU Operation | Data access | Reg Write | Total Time |
| lw | 200ps | 100ps | 200ps | 200ps | 100ps | 800ps |
| sw | 200ps | 100ps | 200ps | 200ps | - | 700ps |
(add, sub, AND, OR, slt) |
200ps | 100ps | 200ps | - | 100ps | 600ps |
(beq) |
200ps | 100ps | 200ps | - | - | 500ps |
[ 단일 사이클과 파이프라인 예시 수행시간 비교 ]
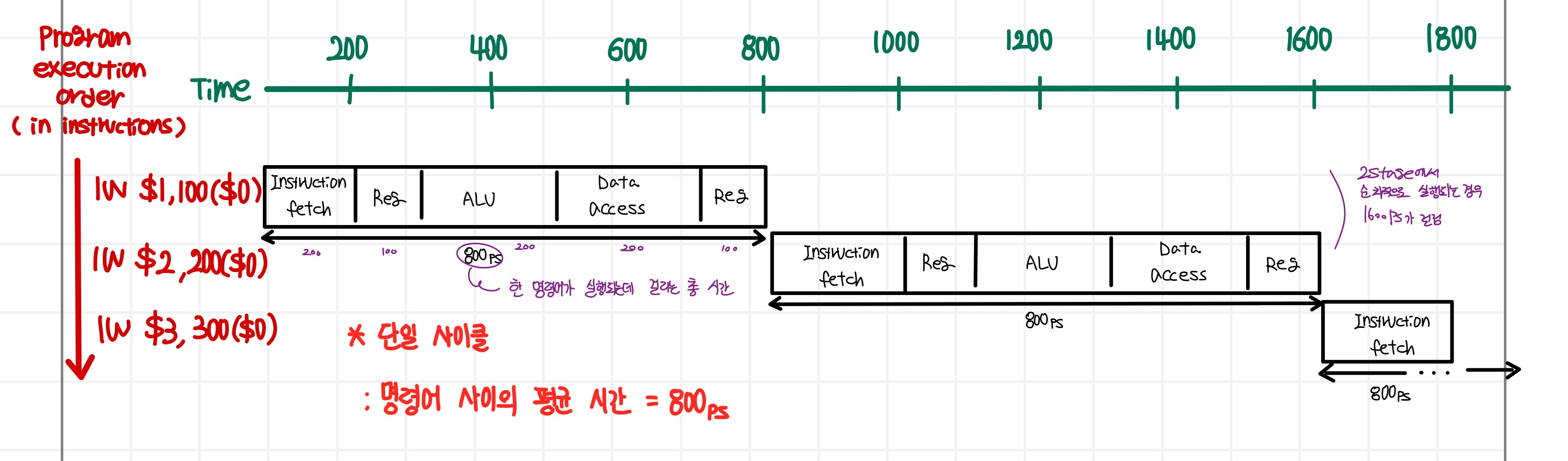

- 단계들이 완벽하게 균형(모든 단계의 처리시간이 같은 파이프라인)을 이루고 있으면, 파이프라인 프로세서 명령어 사이의 시간은 다음과 같다.
명령어 사이의 시간 (파이프라인) = 명령어 사이의 시간 (파이프라이닝 되지 않음) / 파이프 단계 수
4. 파이프라이닝을 위한 명령어집합 설계
- MIPS 명령어집합은 원래 파이프라이닝 실행을 위해 설계된 것이다. (MIPS에서 파이프라이닝을 하기 좋은 이유)
[ 파이프라이닝 처리대상(MIPS 명령어집합 설계)의 특징 ]
(1) 모든 MIPS 명령어는 같은 길이를 갖는다. * 모든 명령어는 32bit를 가짐
: 이 같은 제한조건은 첫 번째 파이프라인 단계에서 명령어를 가져오고, 그 명령어들을 두 번째 단계에서 해독하는 것을 훨씬 쉽게 해준다.
cf) Intel x86(CISK) : 복합명령어 (길이 천차만별) <-> MIPS(RISK) : 길이 고정 (정렬제약 - 4byte)
(2) MIPS는 몇 가지 안 되는 명령어 형식을 가지고 있다.
- 모든 명령어에서 근원지 레지스터 필드는 같은 위치에 있다.
- 이와 같은 대칭성은 두 번째 단계에서 하드웨어가 어떤 종류의 명령어가 인출되었는지를 결정하는 동안, 레지스터 파일 읽기를 동시에 할 수 있다는 것을 의미한다.
- 즉, 명령어를 디코딩 하는 시간이 얼마 안걸리고 일정하다. * 명령어 디코딩 : 명령어가 의미하는대로 연산을 수행하기 위해서, 필요한 레지스터를 선택하고, ALU에게 어떤 연산을 수행해야 하는지 해석하는 것.
cf) R-format, I-format, J-format
(3) MIPS에서는 메모리 피연산자가 적재(lw), 저장(sw)에서만 나타난다. * MEM 단계가, lw, sw에서만 드러난다.
- 이와 같은 제한은 메모리 주소를 계산하기 위해, 실행 단계를 사용하고, 다음 단계에서 메모리에 접근할 수 있다는 것을 의미한다.
cf) Intel x86 (단계 3 - 단계4) : 주소 단계 - 메모리 단계 - 실행 단계 확장 됨.
(4) 피연산자는 메모리에 정렬되어 있어야 한다.
- 이는 한 데이터 전송 명령어가 두 번의 데이터 메모리 접근을 요구할까봐 걱정할 필요가 없다는 것이다. 즉, 파이프라인 하나에서 프로세서와 메모리가 필요한 데이터를 주고받을 수 있다.
5. 파이프라인 해저드
: 다음 명령어가, 다음 클럭사이클(단계)에 실행될 수 없는 상황
: 구조적 해저드, 데이터 해저드, 제어 해저드가 있다.
1) 구조적 해저드
: 다른 단계에 있는 명령어들이 동시에 같은 자원을 사용하려 하는 상황. -> 해당 자원을 여러개 설치함으로서 해결.
① 구조적 해저드 정의 및 해결책
- 같은 클럭사이클에 실행하기를 원하는 명령어의 조합을, 하드웨어가 지원할 수 없는 상황. 따라서 계획된 명령어가 적절한 클럭사이클에 실행될 수 없는 사건.
- MIPS 명령어 집합은 파이프라이닝하도록 설계되어 있기 때문에, 설계자가 파이프라인을 설계할 때 구조적 해저드를 피하는 것이 비교적 용이하다.
② 구조적 해저드 예제
- lw명령어로 데이터 메모리를 읽을 경우(MEM), IF에서 다음 명령어를 메모리에서 가져오려고 하면 충돌이 나게 된다.
- 이와같이 만약 메모리가 1개밖에 없다면, 데이터 메모리를 먼저 사용한 다음에, IF에서 바로 다음 명령어를 가져오지 않고 한 타임 쉰다.
| IF | ID | EX | MEM | WB | |
| 1 | lw | ||||
| 2 | add | lw | |||
| 3 | sub | add | lw | ||
| 4 | (bubble) | sub | add | lw | |
| 5 | beq | (bubble) | sub | add | lw |
- 해결책
: 메모리 분리(Instruction Memory, Data Memory), ALU 이외 (PC계산 Adder, 주소 계산 Adder) 추가하기.
: 즉, 잘 설계된 파이프라인에서는 구조적 해저드가 없으므로, 설계자가 사전에 주의할 필요가 있다.
2) 데이터 해저드
: 앞 명령어 결과를 사용해야 하는데, 앞이 아직 끝나지 않아 사용하지 못하는 상황 -> 파이프라인 지연, 전방전달로 해결 가능
① 데이터 해저드 정의와 원인
- 정의
: 어떤 단계가 다른 단계가 끝나기를 기다려야 하기 때문에, 파이프라인이 지연되야 하는 경우 일어난다.
: 명령어를 실행하는데 필요한 데이터가 아직 준비되지 않아서, 계획된 명령어가 적절한 클럭사이클에 실행될 수 없는 사건
- 원인
: 컴퓨터 파이프라인에서는 어떤 명령어가 아직 파이프라인에 있는 앞선 명령어에 종속성을 가질 때 발생한다.

② 데이터 해저드 해결책
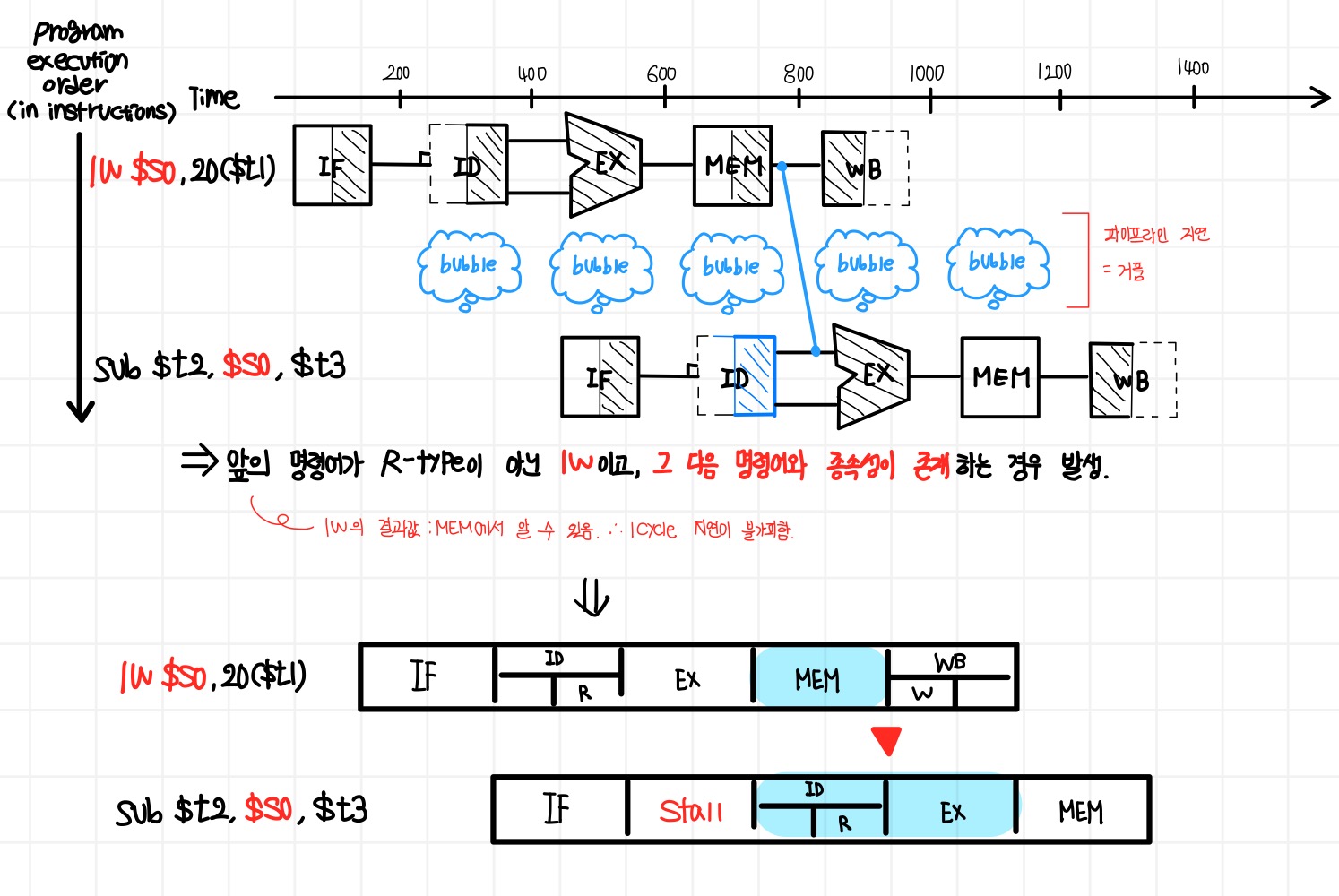
1. Stalling (Hardware 개선)
: 구조적 해저드처럼 하드웨어를 추가하거나, 거리를 벌리고 그 차이만큼 bubble을 넣어준다.

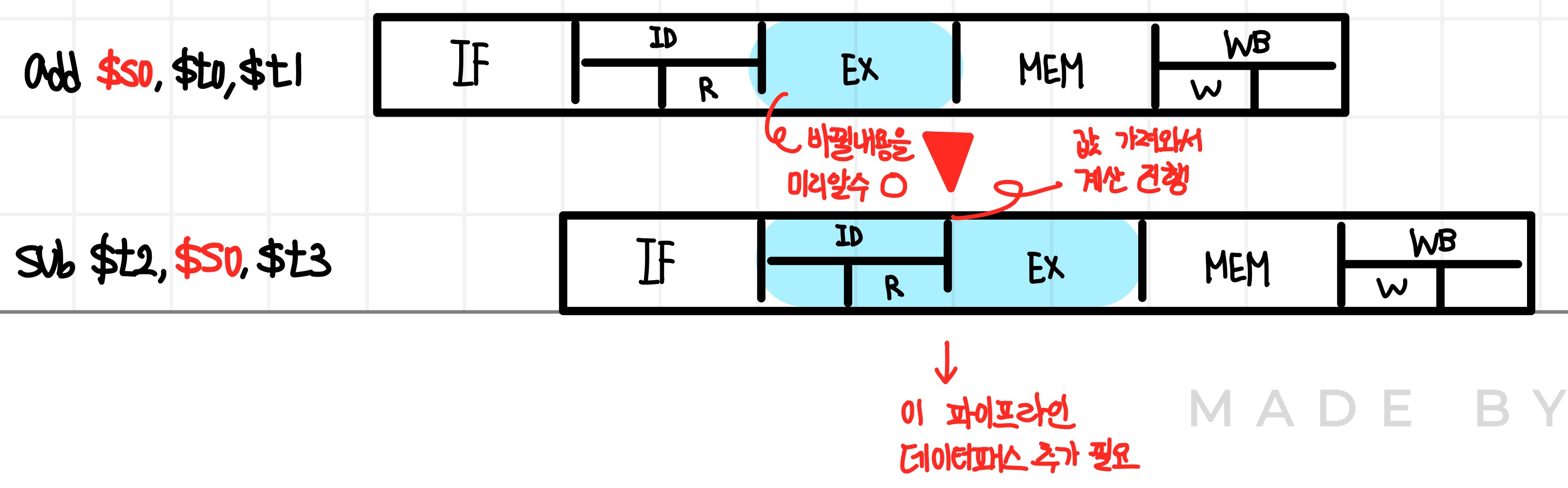
2. 전방전달(=우회전달) (Hardware 개선)
: 레지스터나메모리에 아직 나타나지 않은 데이터를 기대하기보다는, 내부 버퍼로부터 가져옴으로써 데이터 해저드를 해결하는 방법. 즉, 별도의 하드웨어를 추가하여, 정상적으로는 얻을 수 없는 값을 내부 자원으로 일찍 받아오는 것을 말한다.
ex 1) ALU result to next Instruction (Stall 없음)

ex 2) Load result to next Instruction (Stall 1개)
3. Compiler Sceduling (Software 개선)
a. NOP(Instruction Refresh)
: 거리를 벌리고 그 사이에 NOP을 채운다. (NOP은 가상명령어)
: 하드웨어 추가가 필요 없지만, 두 클락을 낭비하게 된다. (sw 차원의 bubble과 같음)

b. Code Sceduling
: 의존성에 문제가 없게 앞이나 뒤에 있는 명령어를 바꿔준다.
: 문제가 없는 명령어를 찾을 확률이 낮다.
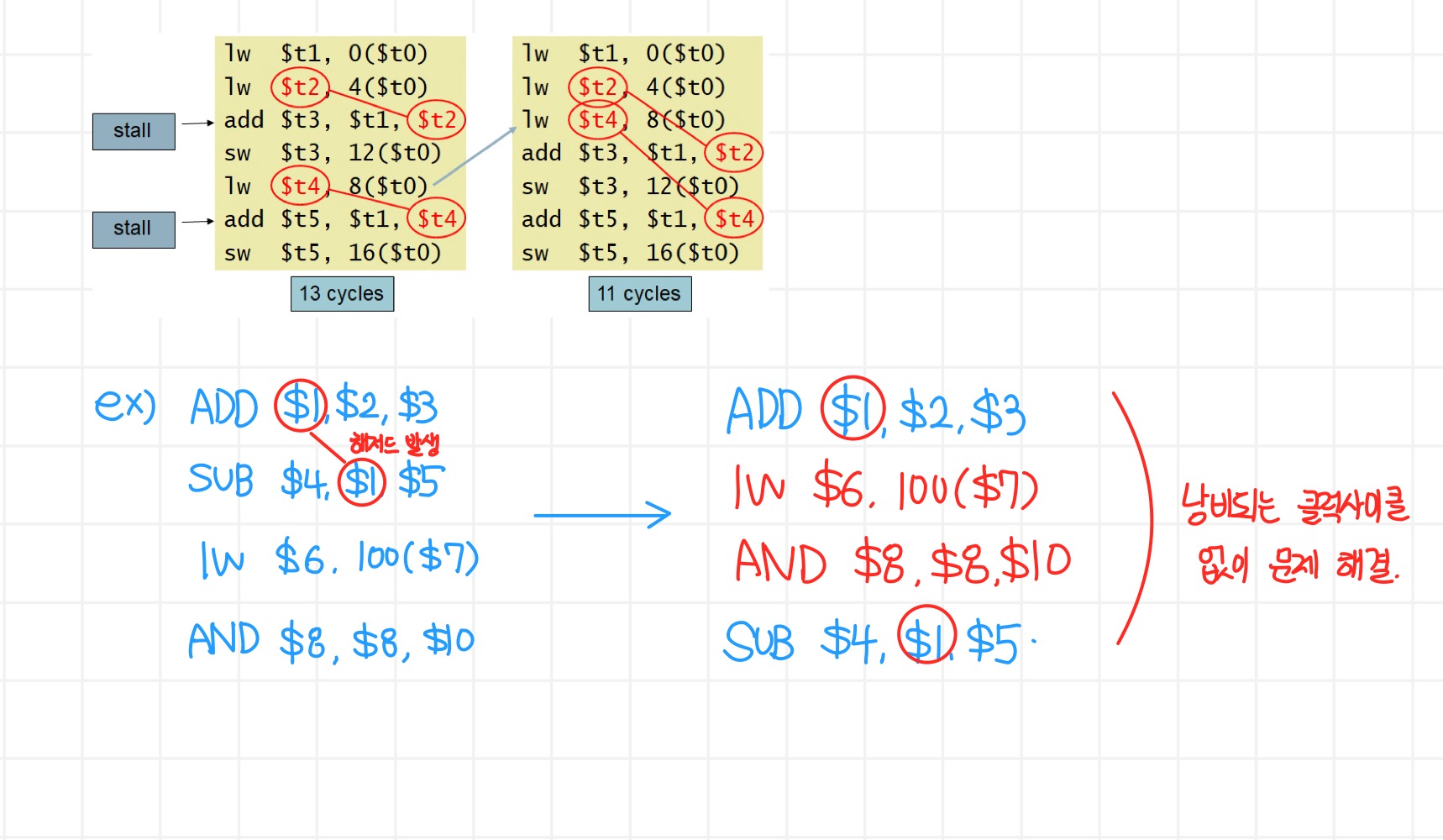
ex) 파이프라인 지연을 피하기 위한 코드의 재정렬
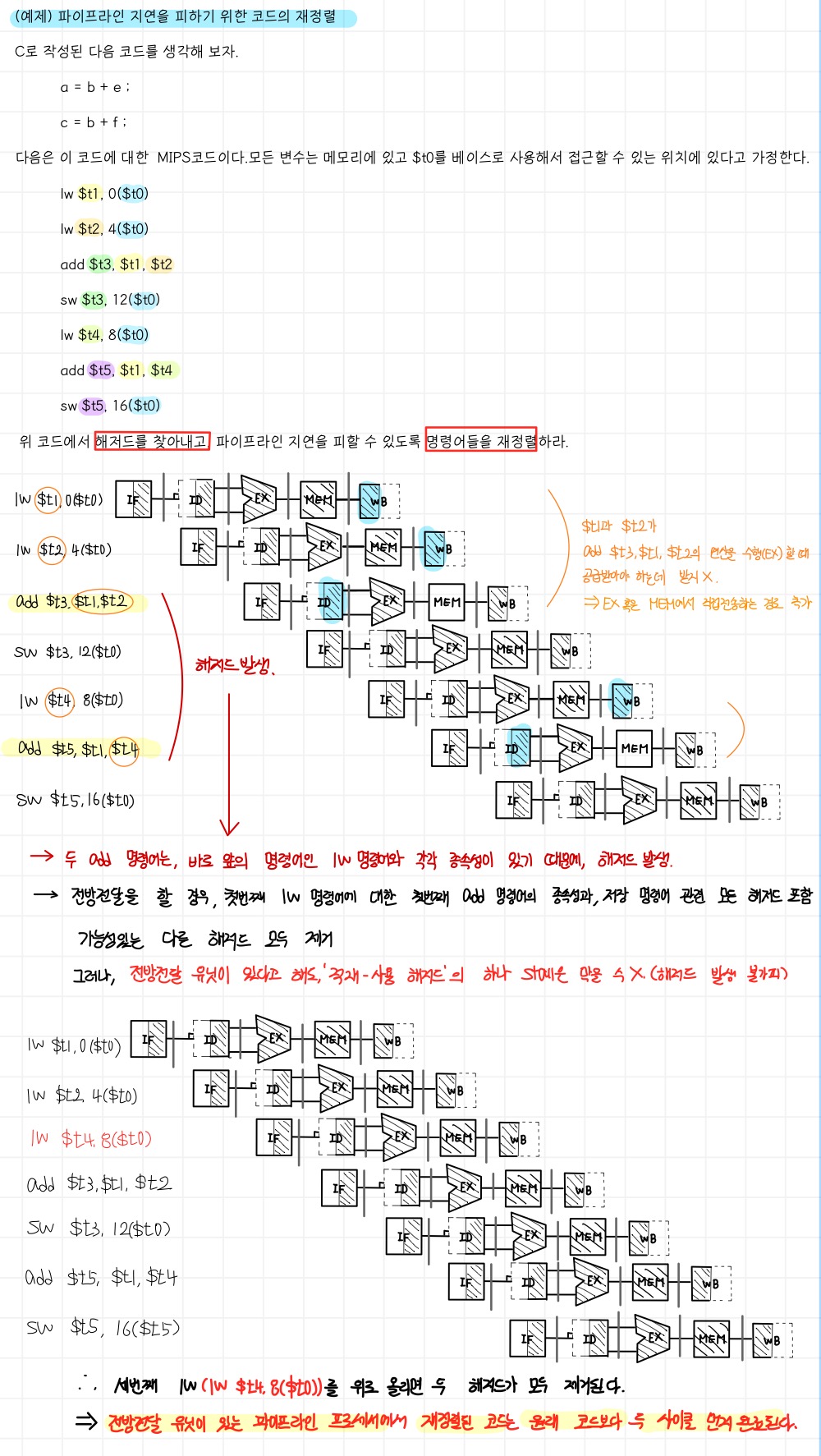
3. 제어 해저드
: 앞 분기 명령어 결과를 몰라서, 다음 명령어를 인출하지 못하는 상황 -> 파이프라인 지연, 분기예측, 지연분기로 해결 가능.
① 제어 해저드의 정의
- 다른 명령어들이, 실행 중에 한 명령어의 결과값에 기반을 둔, 결정을 할 필요가 있을 때 발생한다.
- 인출한 명령어가 필요한 명령어가 아니기 때문에, 적절한 명령어가 적절한 클럭사이클에 실행될 수 없는 사건을 말한다. 즉, 명령어 주소의 흐름이, 파이프라인이 기대한 것과 다르기 때문에 발생한다.
② 제어 해저드의 해결책
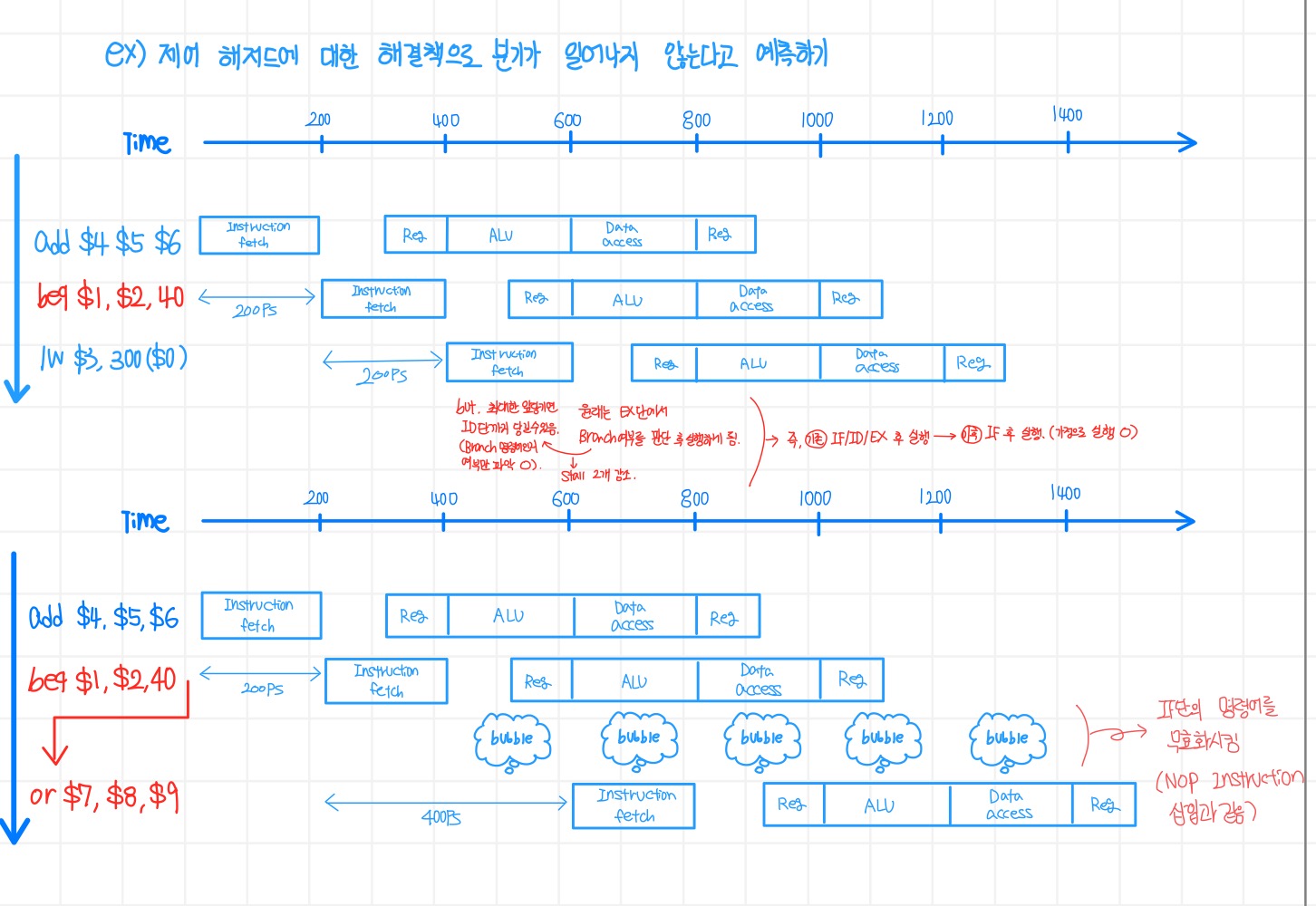
1. 지연(Stall) (Hardware적 개선)
: 분기 명령어를 가져온 직후, 지연시켜서 파이프라인이 분기의 결과를 판단하고, 어느 주소에서 다음 명령어를 가져올지 알게 될 때 까지 기다리게 하는 것이다.

2. 예측 (Hardware적 개선)
a. Static Branch Prediction
가장 기본적인 것은, 분기가 무조건 안될거라고 예측하기.
- 분기가 안되면 : 파이프라인 명령어 순서대로, 최고속도로 진행
- 분기가 된다면 (예측이 틀리면) : 다음 명령어 flush 진행(1 clock 손해), 이후 Branch target 명령어를 넣는다.
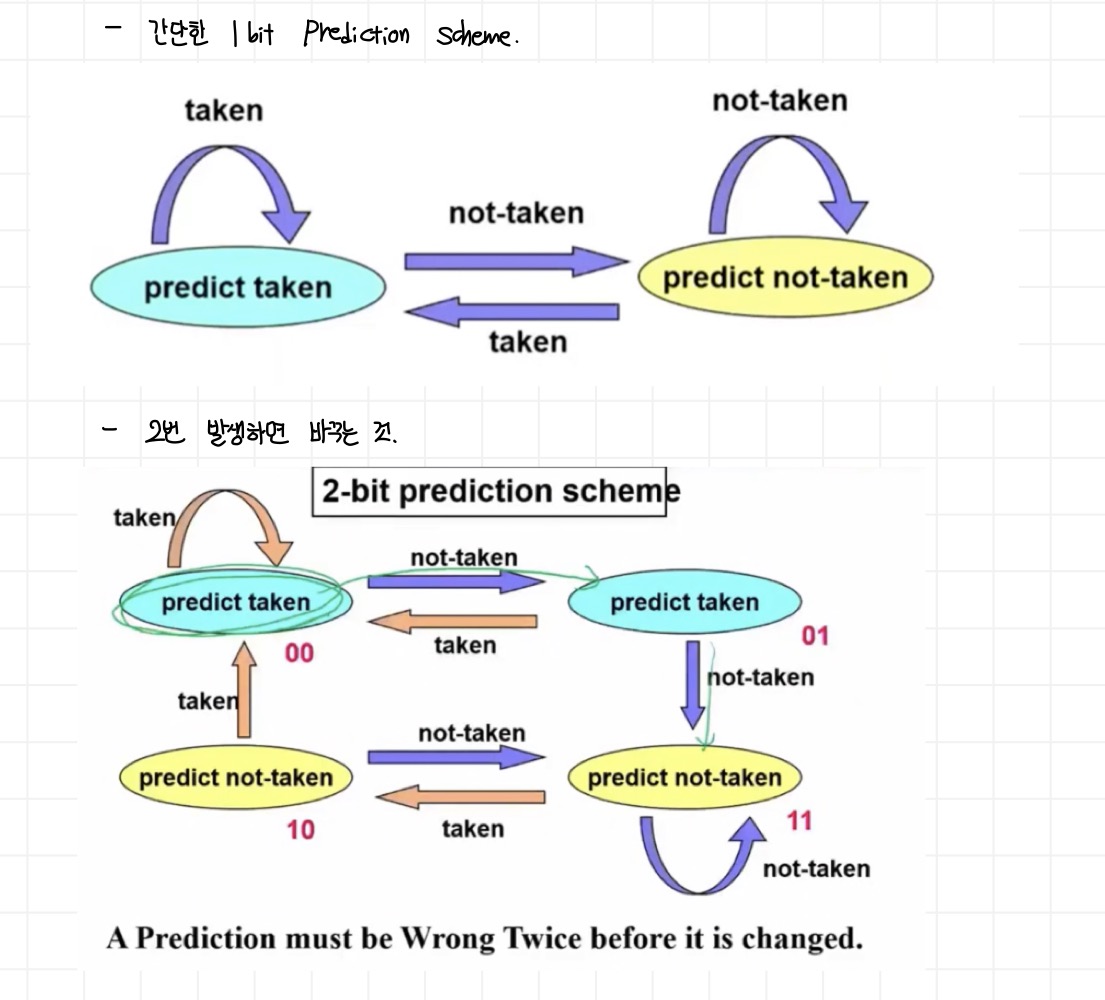
b. Dynamic Hardware Predictior
- 정적 분기 예측 방법이 보편적 행동에 의존하며, 특정 분기 명령어의 개별성은 고려하지 않는 것과 반대로, 이는 개별 분기 명령어의 행동에 의존하는 예측을 하며, 프로그램이 진행되는 도중에 예측을 바꿀 수 있다.
- 방법 : 각 분기가 일어났는지 안 일어났는지에 대한 이력을 기록하고, 최근의 과거 이력을 통해 미래를 예측한다. 예측이 어긋났을 때는 잘못 예측한 분기 명령어 뒤에 나오는 명령어들을 무효화하고, 올바른 분기 주소로부터 파이프라인을 다시 시작해야 한다.
- 최근에는 정보나 이력이 많아져, 이 방법(동적분기)의 예측기가 90% 이상의 정확도를 가지게 되었다.
| * 유의사항 - 아직 공부하고 있는 문과생 코린이가, 정리해서 남겨놓은 정리 및 필기노트입니다. - 정확하지 않거나, 틀린 점이 있을 수 있으니, 유의해서 봐주시면 감사하겠습니다. - 혹시 잘못된 점을 발견하셨다면, 댓글로 친절하게 남겨주시면 감사하겠습니다 :) |
'문과 코린이의, [컴퓨터 구조] 기록 > 컴퓨터구조 4강' 카테고리의 다른 글
| [문과 코린이의 IT기록장] 컴퓨터 구조 - 4.6. 파이프라인 데이터패스 및 제어 (1) | 2021.01.20 |
|---|---|
| [문과 코린이의 IT 기록장] 컴퓨터 구조 - 4.4. 데이터패스의 단순한 구현 (1) | 2021.01.17 |
| [문과 코린이의 IT기록장] 컴퓨터 구조 - 4.3. 데이터패스 만들기 (2) | 2021.01.17 |
| [문과 코린이의 IT 기록장] 컴퓨터 구조 - 4.2.논리 설계 관례 (0) | 2021.01.17 |
| [문과 코린이의 IT기록장] 컴퓨터 구조 - 4.1. 프로세서(CPU) (0) | 2021.01.17 |



